El data lakehouse combina lo mejor del data lake y del data warehouse. Conoce su arquitectura, beneficios y tendencias clave en la nube.
Durante mucho tiempo, las empresas guardaban su información en data warehouses: grandes almacenes de datos pensados para organizar la información en tablas bien estructuradas y responder a preguntas a través de consultas en SQL. Eran muy útiles, pero también caros y poco prácticos cuando se trataba de manejar datos más modernos, como documentos, imágenes o información en formatos menos rígidos.
Para cubrir esa necesidad aparecieron los data lakes: repositorios más económicos y flexibles, capaces de guardar cualquier tipo de datos en su estado original. Sin embargo, tenían un problema importante: carecían de reglas claras de organización y de mecanismos sólidos de control. Eso hacía que, con el tiempo, la calidad de los datos se viera comprometida y que acceder a la información correcta fuera complicado.
Como respuesta a estas limitaciones surge el data lakehouse, una arquitectura que combina lo mejor de ambos mundos. Ofrece la flexibilidad y bajo coste de un data lake, pero con la estructura, el control y la confiabilidad de un data warehouse.
En este artículo exploraremos en detalle qué es una lakehouse, cuáles son sus principales ventajas y cómo encaja en una estrategia de datos moderna. También revisaremos las tendencias más recientes que están marcando la evolución de este enfoque.
¿Qué es un Data Lakehouse?
Un Data Lakehouse es una arquitectura de datos flexible que combina la agilidad de un data lake con las capacidades analíticas y la estructura de un data warehouse.
Una fusión de dos enfoques
- Del data lake, hereda la capacidad de almacenar grandes volúmenes de información en bruto, de cualquier tipo: datos estructurados (tablas), semiestructurados (logs, JSON) o no estructurados (imágenes, vídeos, sensores IoT).
- Del data warehouse, incorpora herramientas avanzadas para organizar esos datos, consultarlos con eficiencia y aprovecharlos en proyectos de business intelligence.
En otras palabras, un data lakehouse permite guardar los datos tal y como son, sin necesidad de transformarlos al inicio, y al mismo tiempo ofrece la estructura y la velocidad necesarias para analizarlos fácilmente.
El valor de un único sistema
El objetivo de un data lakehouse es reunir en un solo lugar la escala y bajo coste de un data lake, junto con la organización, data governance y rapidez de un data warehouse. Esto resuelve un problema muy común: la fragmentación de datos.
En las arquitecturas tradicionales de dos niveles (lake + warehouse), los datos se duplicaban y transformaban varias veces, lo que aumentaba los costes y generaba retrasos. Con un lakehouse:
- Se aprovechan los formatos abiertos y económicos del data lake (Parquet, ORC, Delta) con la fiabilidad de las transacciones de un warehouse.
- Un único repositorio centraliza todas las fuentes de datos, evitando migraciones repetitivas y asegurando que la información esté siempre actualizada.
- Los motores de consulta de nueva generación permiten ejecutar SQL de alto rendimiento, gracias a capas de metadatos que indexan los archivos y garantizan transacciones ACID.
- Los equipos de ciencia de datos pueden acceder directamente a los archivos para entrenar modelos de machine learning con herramientas como Spark, pandas o TensorFlow.
Una única fuente de verdad
En la práctica, el data lakehouse se convierte en la fuente única de la verdad dentro de una organización: elimina los silos, evita copias redundantes y permite que tanto los proyectos de Big Data como los de inteligencia de negocio convivan en la misma plataforma.
Esto significa que es posible ejecutar, sobre un mismo sistema, cargas de trabajo muy diferentes: desde informes de BI hasta entrenamientos de modelos de IA o análisis de datos en tiempo real.
Arquitectura de una Lakehouse
Componentes clave
-
Almacenamiento de bajo coste. Basado en almacenamiento de objetos (Azure Blob, Amazon S3, Google Cloud Storage) para datos en bruto.
-
Capa de metadatos. Tecnologías como Delta Lake registran los archivos que componen cada tabla, permiten transacciones ACID, garantizan el control de versiones y la validación de esquemas.
-
Motor de consulta. Nuevos motores SQL optimizan el acceso a datos almacenados en la lakehouse mediante cachés, índices, ejecución vectorizada y ordenamiento de datos.
-
Capa de gobernanza. Permite definir quién puede acceder a qué datos, auditoría y cumplimiento normativo.
-
Interfaces de acceso. Herramientas de BI (como Power BI) se conectan mediante endpoints SQL; los científicos de datos usan APIs de Spark, pandas o TensorFlow.
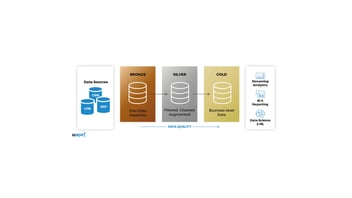
Arquitectura Medallion: Bronze, Silver y Gold
Una de las prácticas recomendadas dentro de un data lakehouse es aplicar un diseño por capas de calidad conocido como arquitectura Medallion (arquitectura del medallón o multisalto).
Propuesta originalmente por Databricks, la arquitectura Medallion es un enfoque que organiza lógicamente los datos en un lakehouse en tres capas secuenciales (Bronze, Silver y Gold), promoviendo la mejora de la calidad de datos a medida que avanzan desde su estado bruto hasta información lista para el negocio.
En otras palabras, cada capa del medallion representa un nivel de refinamiento del dato, con validaciones y transformaciones que garantizan integridad y utilidad crecientes.
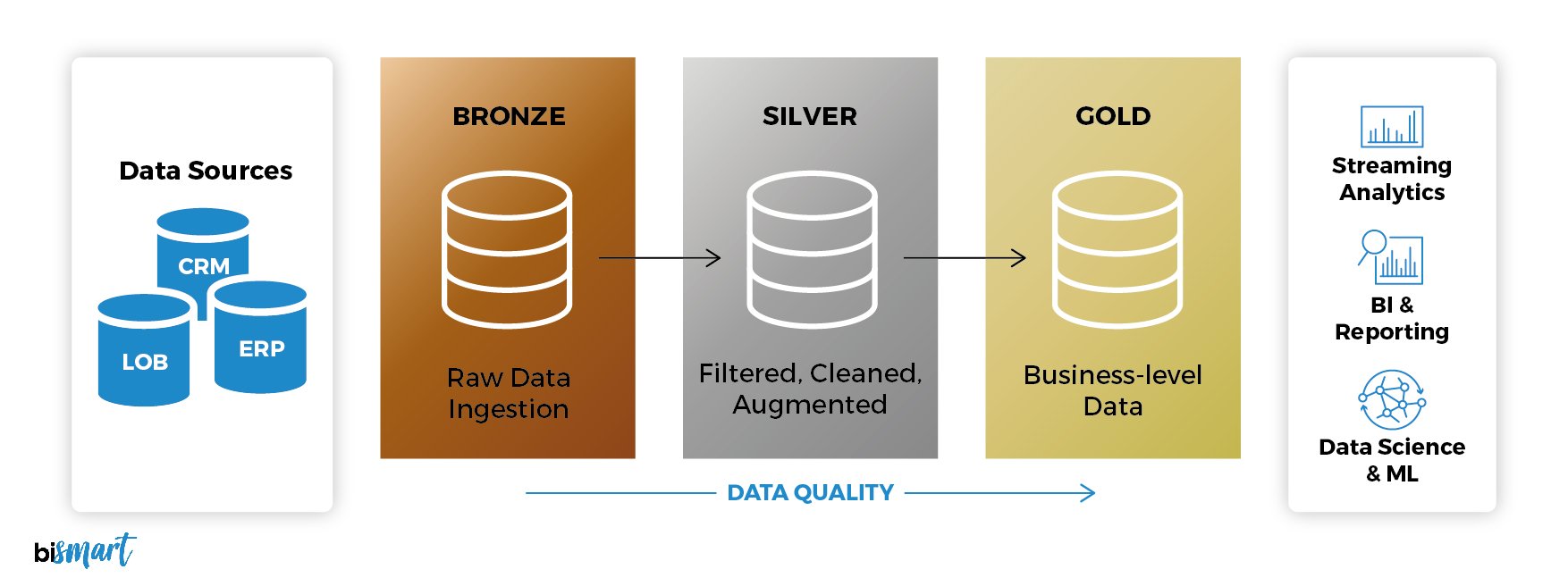
- Capa Bronze (datos en bruto): En esta primera capa se almacenan los datos tal como llegan, en su formato original, acompañados de metadatos que indican su procedencia y momento de carga. Su objetivo principal es conservar una copia histórica y auditable de todo lo que entra en el sistema. Esto la hace especialmente útil para tareas como capturar cambios en los datos (change data capture) o volver a procesarlos en el futuro si es necesario.
- Capa Silver (datos validados): Aquí los datos de la capa Bronze se limpian, depuran y estandarizan para ofrecer una visión empresarial unificada. Es el punto en el que, por ejemplo, se eliminan duplicados en catálogos de clientes o productos y se garantiza que la información siga reglas consistentes. En esta capa se aplican transformaciones ligeras y modelos que aseguran la coherencia de los datos.
- Capa Gold (datos curados): En esta última etapa, los datos ya están listos para el análisis de negocio. Se organizan en modelos optimizados para casos concretos como ventas, marketing o recomendaciones de productos. Además, se aplican reglas estrictas de calidad y se construyen data marts especializados que permiten a los equipos de negocio obtener información directa y accionable.
Este patrón de capas tiene una gran ventaja: asegura la trazabilidad de los datos. Siempre es posible reconstruir cualquier tabla o modelo partiendo de la información original en Bronze. Así, se combina la flexibilidad de tener los datos en bruto con la fiabilidad de contar con versiones validadas y preparadas para la toma de decisiones.
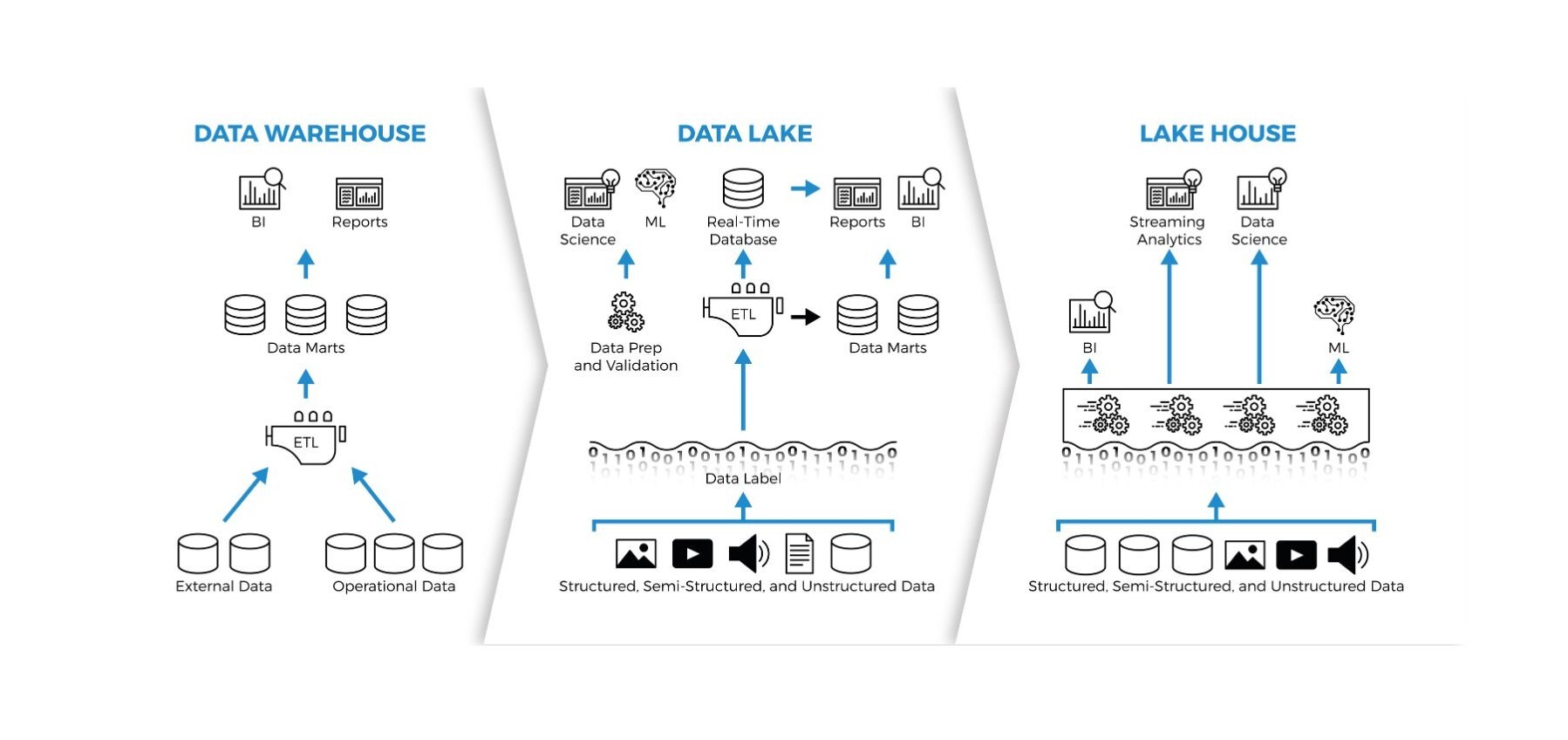
Data Warehouse vs. Data Lake vs. Data Lakehouse
Para entender qué aporta un data lakehouse, es útil compararlo con sus predecesores: el data warehouse (almacén de datos) y el data lake (lago de datos). Cada uno nació para resolver una necesidad concreta, pero también con sus limitaciones.
Comparación: Data Warehouse vs. Data Lake vs. Data Lakehouse
| Tecnología | Uso principal | Ventajas clave | Limitaciones |
|---|---|---|---|
| Data Warehouse | Analizar datos estructurados y dar soporte a BI (business intelligence). | Alto rendimiento en consultas SQL; datos de calidad; transacciones seguras (ACID). | Coste elevado; difícil de escalar; sólo admite datos muy estructurados. |
| Data Lake | Almacenar grandes volúmenes de datos en bruto (estructurados, semiestructurados y no estructurados). | Escalable y económico; gran flexibilidad para guardar cualquier tipo de formato. | No ofrece transacciones fiables; carece de gobernanza; acceso más lento. |
| Data Lakehouse | Plataforma unificada que soporta análisis, operaciones y aplicaciones de IA. | Reúne lo mejor de ambos mundos: almacenamiento barato con gestión de datos, transacciones y alto rendimiento. Evita duplicar procesos ETL y facilita machine learning. | Tecnología aún en evolución; requiere adoptar nuevos patrones (como el modelo Medallion) y herramientas especializadas. |
Data Lakehouse en Microsoft Fabric
En la nube, el enfoque lakehouse simplifica de forma notable los flujos de datos. Los equipos ya no necesitan mantener dos infraestructuras separadas —una para almacenar datos en bruto y otra para analizarlos—. Con un lakehouse basta con ingestar los datos una sola vez y habilitar a partir de ellos múltiples usos: desde dashboards de BI hasta análisis predictivos, machine learning o proyectos de inteligencia artificial.
El concepto de lakehouse fue inicialmente impulsado por compañías pioneras como Databricks, y pronto los grandes proveedores de nube lo incorporaron a sus servicios. Entre ellos, Microsoft destaca con Microsoft Fabric, que incluye un componente nativo de Lakehouse pensado para ofrecer análisis unificados en una misma plataforma.
El Data Lakehouse en Microsoft Fabric representa la evolución natural de la gestión de datos en la nube. Gracias a esta arquitectura, los flujos de trabajo se vuelven más simples, flexibles y eficientes, lo que permite a las organizaciones responder con rapidez a las necesidades actuales y acelerar la innovación.
SQL Analytics Endpoint de Microsoft Fabric
Una de las ventajas más prácticas es que, al crear una lakehouse en Microsoft Fabric, se genera automáticamente un endpoint de SQL analítico. Este recurso ofrece una interfaz relacional de solo lectura sobre las tablas Delta, lo que permite:
- Ejecutar consultas en T-SQL de manera sencilla.
- Crear modelos semánticos directamente para Power BI.
En la práctica, esto significa que los usuarios de negocio pueden acceder a los datos con herramientas familiares, sin tener que enfrentarse a la complejidad técnica que hay detrás de la arquitectura lakehouse.
Beneficios clave de un Data Lakehouse
Adoptar un data lakehouse aporta ventajas significativas para las organizaciones que buscan simplificar su gestión de datos y obtener más valor de ellos. Entre los beneficios más destacados se encuentran:
1. Datos unificados y sin duplicados
Un lakehouse consolida toda la información en una sola plataforma, evitando silos y copias innecesarias. Esto facilita trabajar con una única “fuente de la verdad”, asegurando que todos los equipos consulten los mismos datos actualizados y confiables.
2. Reducción de costes
Aprovecha el almacenamiento económico en la nube (como AWS S3 o Azure Data Lake) y elimina la necesidad de mantener infraestructuras separadas para almacenamiento y análisis. De este modo, se reducen de manera significativa los costes frente a los tradicionales data warehouses.
3. Soporte para todo tipo de análisis
Un lakehouse bien diseñado permite trabajar con distintos escenarios: desde informes de negocio y visualización hasta ciencia de datos, machine learning o análisis de datos avanzado. Todo ocurre sobre los mismos datos, sin tener que moverlos entre sistemas.
4. Mayor gobernanza y calidad de datos
A diferencia de los data lakes tradicionales, el lakehouse incorpora mecanismos de organización y gobernanza. Esto significa que los datos se validan conforme a reglas y políticas antes de ser considerados “confiables”, evitando que la plataforma se convierta en un repositorio caótico.
5. Escalabilidad y alto rendimiento
En la nube, el lakehouse separa el almacenamiento del procesamiento. Así es posible escalar de forma flexible: distintos motores (SQL, Spark, etc.) pueden trabajar en paralelo sobre los mismos datos, sin duplicarlos ni generar bloqueos.
6. Datos en tiempo real
El lakehouse está preparado para manejar flujos de datos en streaming, como los que generan sensores IoT, aplicaciones o registros de actividad. Esto permite análisis y respuestas en tiempo real, clave para sectores que requieren inmediatez en la información.
Tendencias futuras: hacia el Lakehouse 2.0 y más allá
El mundo de los datos está en constante transformación. Así como los data warehouses tradicionales dieron paso a los data lakehouses, ya se vislumbran los primeros pasos hacia una nueva generación conocida como “Lakehouse 2.0”. Esta evolución busca superar las limitaciones de la primera ola de lakehouses y adaptarse a los retos actuales: mayor apertura, modularidad y análisis en tiempo real.
Ecosistemas más abiertos y flexibles
Una de las principales tendencias es el auge de formatos de tabla abiertos como Apache Iceberg, Delta Lake o Apache Hudi. Estos formatos permiten que diferentes motores y plataformas trabajen sobre los mismos datos, sin depender de un único proveedor. El resultado es un ecosistema más flexible, donde almacenamiento y cómputo se desacoplan y las organizaciones pueden elegir libremente las herramientas que mejor se adapten a sus necesidades.
Capas semánticas integradas
Otra innovación clave es la incorporación de modelos semánticos unificados dentro del propio lakehouse. Esto significa que métricas, indicadores y reglas de negocio dejan de definirse de forma aislada en cada herramienta de BI. En su lugar, toda la organización utiliza un único modelo centralizado, asegurando que los KPIs se calculen siempre de la misma manera y evitando reprocesamientos innecesarios.
Data contracts y confianza entre equipos
El Lakehouse 2.0 también impulsa la idea de los data contracts: acuerdos formales entre quienes generan los datos y quienes los consumen. Estos contratos establecen qué formato, calidad y frecuencia deben tener los datos, lo que aporta mayor confianza, transparencia y colaboración entre equipos.
Apuesta de proveedores y comunidad open-source
Las grandes tecnológicas y la comunidad open-source ya están impulsando este nuevo paradigma:
- Microsoft ha lanzado Fabric, una plataforma que integra data engineering, data warehousing y data lakes en un único servicio con el lakehouse como pilar central.
- Databricks sigue evolucionando con su Lakehouse Platform, incorporando catálogos unificados (Unity Catalog), herramientas avanzadas de gobernanza y capacidades de machine learning sobre el mismo repositorio de datos.
- Google ofrece BigLake, que combina el poder de BigQuery con la flexibilidad de los data lakes en una sola capa unificada.
- Incluso los proveedores tradicionales de bases de datos están adaptándose para no quedarse atrás.
Conclusión: Lakehouse como pilar de la estrategia de datos moderna
El data lakehouse se consolida como la base de la arquitectura de datos moderna. Su capacidad para unificar información de distintas fuentes, escalar sin límites en la nube y ofrecer acceso flexible para múltiples usos analíticos lo convierte en una pieza clave en la era del Big Data y la inteligencia artificial.
Cuando se combina con enfoques como el data mesh y prácticas como la arquitectura Medallion, el lakehouse permite que las organizaciones sean verdaderamente data-driven: extraen valor de sus datos de manera más rápida, segura y colaborativa.
Para las empresas que aspiran a liderar en la economía digital, invertir en una estrategia de data lakehouse con buenas prácticas de data quality y data governance ya no es opcional, sino una decisión estratégica que marca la diferencia. La clave está en transformar los datos en una ventaja competitiva real, y en comunicar ese valor de forma clara y efectiva, uniendo la visión técnica con un lenguaje accesible que conecte con todos los niveles de la organización.