Descubre qué es cloud data lake y cloud data lakehouse, las nuevas infraestructuras en la nube más flexibles, escalables y seguras.
En la era digital actual, la gestión eficiente de los datos es esencial para el éxito empresarial. A medida que las cantidades de datos generados por las empresas aumentan, la gestión efectiva de los activos se complica. Las nuevas necesidades de las empresas han provocado el auge de nuevas infraestructuras cloud más flexibles, escalables y dinámicas. Hablamos de cloud data lake y cloud data lakehouse.
En los últimos diez años, la mayoría de corporaciones han migrado sus datos a la nube, apostando por servicios y plataformas cloud para el almacenamiento y gestión de sus activos de datos. Sin embargo, el mundo de la infraestuctura cloud también está evolucionando para adaptarse a las nuevas necesidades de data management de las empresas.
En la actualidad, las corporaciones requieren de soluciones en la nube altamente escalables y capaces de gestionar, integrar, analizar, compartir y proteger fácilmente grandes volúmenes de datos, en prácticamente cualquier formato, sin necesidad de que los datos estén previamente modelados o almacenados en una estructura predefinida.
Estas nuevas necesidades han supuesto un cambio de las soluciones cloud tradicionales, los cloud data warehouse, hacia cloud data lakes. Según el informe de TDWI de 2021 “Data Engineering and Open Data Lakes,”, la industria del software está asistiendo a un cambio masivo de data warehouse en la nube a cloud data lakes debido a la mayor flexibilidad de los data lake.
La flexibilidad inherente a los data lakes permite a los profesionales de datos adoptar el enfoque de "cargar los datos primero y hacer preguntas después", expandiendo así las posibilidades en áreas como business intelligence, análisis predictivo, desarrollo de aplicaciones y otras iniciativas basadas en datos. Este cambio representa una nueva era en la gestión de datos, abriendo horizontes en la era de la toma de decisiones ágil e impulsada por datos.
¿Qué es un cloud data lake?
Un cloud data lake —data lake en la nube— es un repositorio de datos centralizado que permite a las organizaciones almacenar una gran cantidad de datos estructurados, semiestructurados y no estructurados a cualquier escala. Está construido sobre servicios de almacenamiento en la nube, lo que lo hace altamente escalable, rentable y capaz de manejar grandes volúmenes de datos en varios formatos, como texto, imágenes, videos, etc. A diferencia de los datos almacenados en un data warehouse, los datos almacenados en un data lake se suelen procesarse mediante la aproximación ELT, por lo que no se modifican o procesan hasta que se necesitan. Esto proporciona una mayor flexibilidad a los equipos de análisis y ciencia de datos, que no necesitan realizar transformaciones en todos los datos antes de almacenarlos.
Para explicarlo de forma sencilla, nos remontaremos al nombre de los data lakes. Tal y como el nombre indica, un data lake es como un gran lago que recoge información de muchos lugares diferentes, como ríos que fluyen desde diversas fuentes. A diferencia de los data marts (estanques de datos) especializados que se utilizan para propósitos específicos, como finanzas o recursos humanos, donde los datos están organizados de antemano para facilitar la búsqueda, un data lake busca algo más parecido a la naturaleza caótica y diversa de los ríos.
En lugar de tener un esquema rígido y predefinido, como una base de datos tradicional, un data lake tiene la capacidad de almacenar una amplia variedad de datos tal como se presentan, sin forzarlos a un formato particular. Este enfoque permite que el lago de datos contenga datos organizados, semiestructurados y no estructurados, ofreciendo así un terreno más fértil para que los profesionales exploren y analicen la información de manera más libre y creativa. Además, mientras que el procesamiento de los datos en un data warehouse suele partir del enfoque ETL, en un cloud data lake es habitual apostar por un enfoque ELT.
En resumen, podríamos decir que un "cloud data lake" es como un vasto lago virtual que recopila información de diferentes fuentes, ofreciendo a las personas un lugar amplio y flexible para explorar y analizar datos de manera más abierta y sin restricciones.
Características clave de un cloud data lake:
- Escalabilidad: Los data lakes en la nube pueden ampliarse o reducirse fácilmente según el volumen de datos, asegurando que puedan adaptarse a conjuntos de datos en crecimiento.
- Rentabilidad: Los data lakes en la nube aprovechan modelos de precios de pago por uso, permitiendo a las organizaciones pagar solo por los recursos de almacenamiento y procesamiento que utilizan.
- Flexibilidad: Admiten diversos tipos y estructuras de datos, lo que permite a las organizaciones ingerir y almacenar datos en su formato nativo sin necesidad de esquemas predefinidos.
- Integración: Los data lakes en la nube se integran perfectamente con varias herramientas de análisis, marcos de aprendizaje automático y otros servicios en la nube, fomentando un ecosistema de datos integral.
- Capacidades Analíticas: Los usuarios pueden realizar análisis avanzados, exploración de datos y machine learning directamente en los datos dentro del data lake en la nube.
- Seguridad y Cumplimiento: Los proveedores de la nube ofrecen sólidas medidas de seguridad y certificaciones de cumplimiento para garantizar la protección y privacidad de los datos almacenados en el data lake.
Cloud Data Warehouse vs Cloud Data Lake
La principal diferencia entre un data lake y un data warehouse es que un data warehouse típicamente se estructura sobre una base de datos relacional —almacena datos estructurados— y un data lake almacena cualquier tipo de datos —datos estructurados, semiestructurados o no estructurados—.
Mientras que los cloud data warehouses suelen diseñarse y modelarse para un fin concreto, los data lake no siempre tienen un caso de uso predeterminado, lo que ha contribuido a la transformación de ETL hacia ELT. Su utilidad se hace evidente más adelante, como cuando los analistas y cientificos de datos llevan a cabo la exploración de datos para la ingeniería de características, visualización de datos, desarrollo de modelos predictivos, etc.
¿Qué requisitos debe cumplir un cloud data lake?
Para ser una solución de integración cloud realmente valiosa, un data lake debe incorporar un conjunto integral de herramientas que revelen el contenido dentro del data lake, identifiquen los usuarios de los datos y sus patrones de uso, además de ofrecer garantías sólidas de seguridad.
Por otro lado, es fundamental que el cloud data lake tenga capacidades para:
- Permitir el almacenamiento de datos en sus formatos originales
- Facilitar la exploración intuitiva de datos por parte de los usuarios
- Automatizar tareas de gestión de datos rutinarias
- Dar soporte a una amplia variedad de casos de uso y cargas de trabajo, como el intercambio moderno de datos.
- Integrar múltiples flujos de datos con distintas frecuencias, sin imponer cargas excesivas a los equipos de ingeniería de datos responsables de construir estos conductos de datos, y sin restricciones de almacenamiento o rendimiento.
Para abordar estas necesidades, las compañías de software se han volcado en la creación de cloud data lakes modernos: repositorios de datos construidos en la nube que permiten organizar datos estructurados, semiestructurados y no estructurados en sus formas originales, ya sea dentro del propio data lake o en un servicio externo de almacenamiento de objetos.
Con una arquitectura de software apropiada, estos data lakes proporcionan una capacidad y escalabilidad prácticamente ilimitadas para el almacenamiento y procesamiento de datos que se requiera, facilitando la extracción de información valiosa, la obtención de valor de los datos y la identificación de nuevas oportunidades de negocio.
La era del data lakehouse
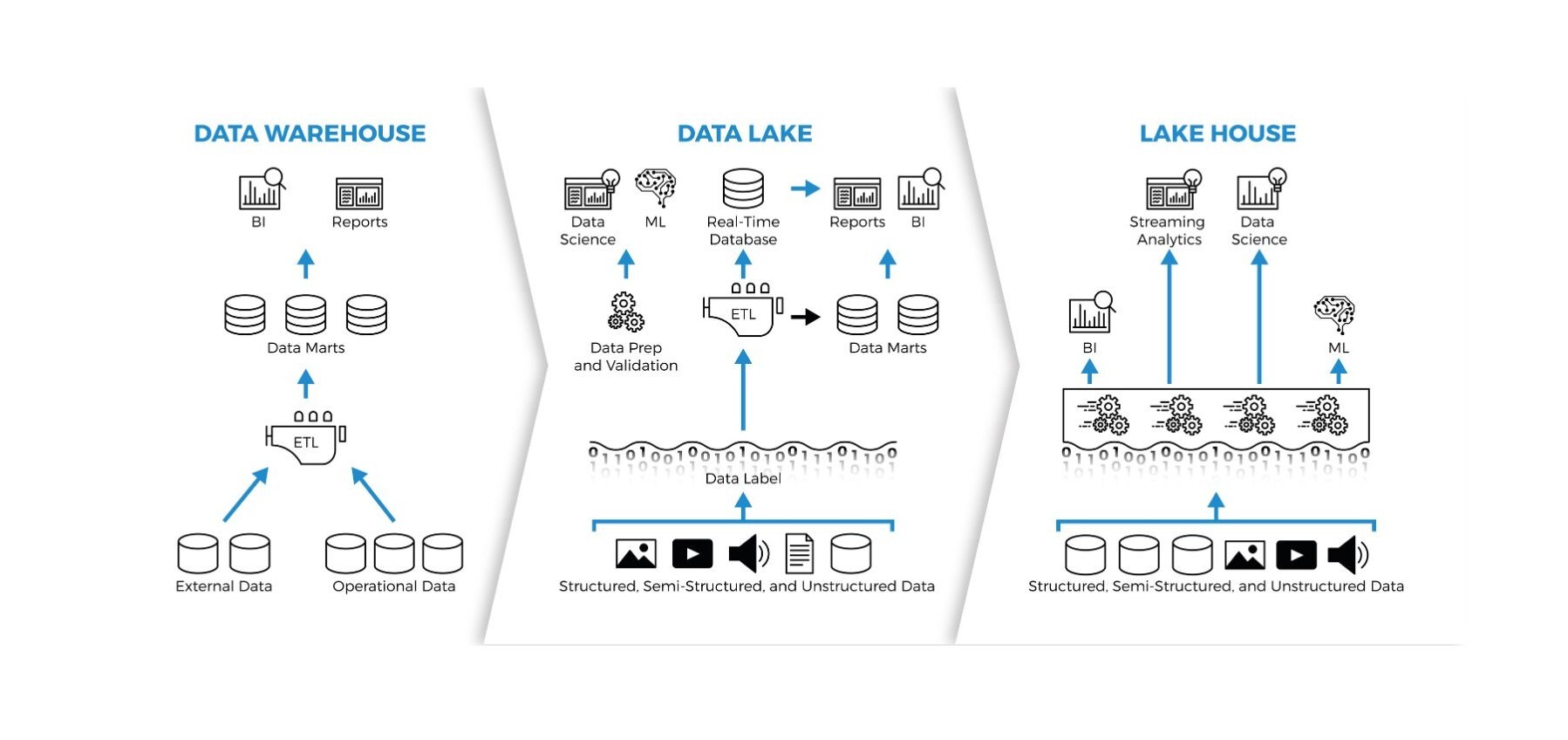
Cloud Data warehouse vs Data Lake vs Data Lakehouse
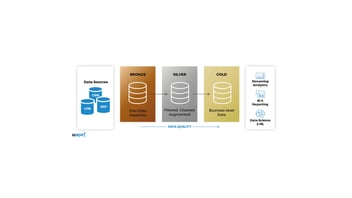
En los últimos años, ha surgido una tendencia en auge que proporciona una nueva forma de organizar y gestionar los datos en la nube: la arquitectura Medallion. Esta arquitectura cloud no solo se alinea con los requisitos de flexibilidad de las empresas, sino que también destaca por confluir con los esfuerzos de data quality.
El auge de la arquitectura medallion, a su vez, ha supuesto la aparición de un nuevo almacén de datos en la nube conocido como data lakehouse., una nueva solución que combina las mejores características del data warehouse y el data lake para abordar las limitaciones y complejidades que presentan estos dos enfoques.
¿Qué es un data lakehouse?
Un data lakehouse es una evolución de los conceptos de data lake y data warehouse, y se sitúa como un término intermedio que busca combinar las ventajas de ambos enfoques. En la arquitectura Medallion, este concepto se manifiesta como una solución integral para gestionar datos en toda su diversidad y proporcionar una plataforma unificada para diversas necesidades de análisis y procesamiento de datos.
El datalakehouse ha surgido cuando el avance tecnológico ha permitido a los proveedores de software diseñar un sistema innovador que compagina las estructuras de datos y funciones de gestión de datos de un data warehouse con el tipo de almacenamiento de objetos de bajo coste utilizado en los data lakes. Este enfoque representa una reimaginación de los almacenes de datos en el mundo moderno, aprovechando el almacenamiento económico y altamente confiable ofrecido por los almacenes de objetos.
La gran ventaja de un data lakehouse es que puede almacenar cualquier tipo de datos, tanto datos estructurados como no estructurados, pero integrando las funcionalidades de modelado de datos de un data warehouse. La tecnología detrás de un data lakehouse permite realizar consultas y manipulaciones en los datos de forma ágil y rápida como en un data warehouse.
Un data lakehouse integra la flexibilidad y capacidad de almacenamiento masivo de un data lake con la estructura organizativa y las capacidades analíticas de un data warehouse. Básicamente, el gran valor del datalakehouse es que tiene la capacidad de almacenar datos tanto datos estructurados, como semiestructurados y no estructurados. De esta manera, permite almacenar datos en su forma bruta, tal como lo haría un data lake, pero también introduce capas de organización y estructuración para facilitar el análisis y la consulta eficientes, características más comúnmente asociadas con un data warehouse.
- Data warehouse: Almacena datos estructurados, por lo que los científicos y analistas de datos deben procesar y estructurar los datos antes de almacenarlos. Esto implica un importante trabajo de previsión a la hora de decidir qué datos se almacenan, cómo se estructurarán y cuáles serán sus casos de uso.
- Data lake: Generalmente usado para almacenar datos semiestructurados o no estructurados.
- Data Lakehouse: Se construye bajo una infraestructura de data lake pero integra las funcionalidades de un data warehouse, por lo que los científicos y analistas de datos pueden almacenar datos estructurados, semiestructurados y no estructurados, evitando así la necesidad de decidir qué se va a hacer con los datos antes de almacenarlos.
Data governance en infraestructuras cloud
A pesar de todas las ventajas ya mencionadas del cloud data lakehouse, es necesario recordar que cualquier tipo de almacén de datos en la nube requiere de la implementación de políticas de data governance para garantizar el uso eficiente de los datos, su protección y el cumplimiento de las normas regulatorias en materia de protección de datos.
La definición de políticas y medidas de data governance también ayuda a garantizar la calidad de los datos, estableciendo estándares y evitando inconsistencias que pueden suponer problemas en el futuro.
Asimismo, controlar el acceso y los roles en entornos de nube colaborativos es esencial para prevenir accesos no autorizados y asegurar la integridad de la información.
Conclusión
En resumen, la evolución de las infraestructuras y almacenes de datos en la nube refleja la creciente necesidad de las empresas de gestionar datos de manera más eficiente y flexible. Desde la migración de datos a la nube hasta la adopción de enfoques como los data lakes y data warehouses en la nube, las organizaciones buscan soluciones que se ajusten a sus demandas cambiantes.
Por ello, en los últimos años, ha surgido una nueva forma de almacenar los datos: el enfoque data lakehouse, que combina las características del data warehouse y el data lake. Este enfoque híbrido permite una gestión más eficiente y un análisis más profundo de los datos, abriendo nuevas oportunidades de negocio y mejorando la toma de decisiones basada en datos.