El Big Data y las nuevas demandas que vinieron con él ha provocado la transformación del proceso ETL hacia una nueva perspectiva: ELT.
El Big Data ha transformado la forma en que los datos se gestionan y almacenan, introduciendo nuevas demandas en cuanto al procesamiento tradicional de almacenaje de datos. Con el tiempo, los nuevos requisitos de volumen y velocidad han transformado los procesos ETL hacia una nueva perspectiva: ELT.

Como ya explicamos en el artículo "¿Qué es ELT y cuáles son sus diferencias con ETL?" en los últimos años ha surgido una nueva forma de abordar los procesos ETL.
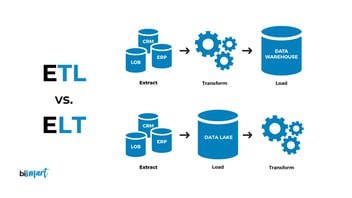
ETL —Extract (Extraer), Transform (Transformar) & Load (Cargar)— es un proceso de carga, almacenaje e integración de datos que lleva en funcionamiento desde los años 70, siendo el método habitual para integrar datos de múltiples fuentes de origen en un único data warehouse. En un proceso ETL los datos se extraen de las fuentes de datos de origen, se transforman en una base de datos provisional y finalmente se cargan al enterprise data warehouse. Este método funcionaba muy bien cuando el data warehouse era una base de datos relacional con esquemas predefinidos, lo que ha convertido ETL en el procedimiento predominante durante los últimos 40 años, con una gran cantidad de herramientas ETL disponibles en un mercado de millones de dólares.
Sin embargo, las nuevas demandas de volumen, velocidad y veracidad en materia de integración y almacenaje de datos han forzado la aparición de una nueva manera de abordar el proceso. ELT —Extract (Extraer), Load (Cargar) & Transform (Transformar)— altera el orden habitual del proceso ETL. Con este nuevo approach, los datos son extraidos de las fuentes de origen y se cargan directamente en el almacén de datos destino. Así, a diferencia de ETL, las transformaciones en los datos se realizan en el propio data warehouse de destino y bajo demanda.
Pero, ¿qué ha pasado con ETL? ¿Por qué ha surgido ELT? ¿Está, el proceso ETL, muerto?
A continuación intentamos resolver estas preguntas.
De ETL a ELT o cómo el Big Data ha transformado el proceso ETL
El término 'Big Data' surgió por primera vez a finales de los años 90 con la intención de dar nombre a la problemática a la que se enfrentaban las organizaciones. Concretamente, en 1997, un grupo de investigadores de la NASA publicaron un artículo en el que se mencionaba que "el aumento de los datos se estaba convirtiendo en un problema para los sistemas informáticos actuales". El incremento de datos generados estimuló el avance tecnológico hacía plataformas que pudieran hacer frente a conjuntos de datos masivos. En 2001, la compañía estadounidense Gartner, publicó una investigación —3D Data Management: Controlling Data Volume, Velocity and Variety— en la que se hablaba por primera vez de las '3V' que tienen que soportar las tecnologías Big Data: volumen, velocidad y variedad.
El Big Data alimentó los primeros desafíos del proceso ETL. El volumen, velocidad y variedad que exige el Big Data puso en entredicho el funcionamiento de las herramientas ETL, en muchas ocasiones incapaces de soportar el ritmo que demanda el procesamiento de conjuntos de datos masivos por falta de capacidad y velocidad, además de suponer sobrecostes.
La aparición de nuevos formatos de datos, fuentes de datos y requisitos relativos a la consolidación de los datos manifestaron la rigidez del proceso ETL, además de cambiar la forma habitual consumir datos. La demanda de más velocidad y variedad provocó que los consumidores de datos necesitaran acceder inmediatamente a los datos en bruto, en lugar de esperar a que el departamento de IT los transformara y haciera accesibles.
Por otro lado, el Big Data también propició la aparición del data lake, un almacén de datos que no requiere de un esquema predefinido a diferencia de lo que hasta el momento había sido el data warehouse, introduciendo esquemas de almacenamiento más flexibles.
Las herramientas ETL, tradicionalmente construidas pensando en la gestión por parte del departamento de IT, son complicadas de instalar, configurar y gestionar. Asimismo, esta tecnología concibe la transformación de datos como una tarea intrínseca de los informáticos, dificultando su acceso a los consumidores de datos que, según la lógica de ETL, únicamente deben poder acceder al producto final almacenado en un data warehouse estandarizado.
Como es habitual, el contexto catapultó la innovación. ELT se concibe como la evolución natural de ETL, remodelando el proceso y haciéndolo más apto para trabajar con Big Data y con servicios cloud, ya que proporciona una mayor flexibilidad. Asimismo, facilita la escalabilidad, mejora el rendimiento y la velocidad y reduce el coste.
Sin embargo, ELT también tiene sus propios problemas. A diferencia de las ETL, las herramientas ELT están diseñadas para facilitar el acceso a los datos a los consumidores finales, lo que democratiza el acceso a los datos permitiendo a los usuarios acceder a ellos desde cualquier fuente de datos a través de una URL. Sin embargo, esto puede poner el riesgo el data governance.
El futuro de la extracción, carga y transformación de datos: ¿ETL o ELT?
Afirmar que ELT ha sustituido definitivamente el proceso ETL es cuanto menos poco razonable. Por ahora, ambos procesos conviven en un mismo entorno y, de hecho, su combinación ya tiene nombre: ETLT. Como es lógico, deshacerse de todas las tecnologías e inversiones hechas en ETL para invertir en ELT no es rentable para ninguna corporación. Por otro lado, aquellas compañías que aún no han invertido en ninguno de los dos procesos, deben evaluar sus necesidades en cuestión de integración de datos para decidir qué propuesta les encaja mejor.
Y es que, además de la gobernanza de datos, ELT también presenta otras contradicciones.
A pesar de optimizar tanto la E como la L, ELT se sigue quedando corto en la T. Hoy en día el análisis de datos cumple un papel fundamental en las empresas. A pesar de los esfuerzos de este nuevo enfoque, el análisis, basado en la transformación de los datos, no se ha simplificado y sigue siendo competencia del departamento de IT, especialmente de ingenieros y científicos de datos. Asimismo, transformar los datos en bruto en activos preparados para ser usados por sus consumidores sigue precisando de varias herramientas y procesos complejos que, evidentemente, los consumidores de los datos no tienen la capacidad de abordar. Por otro lado, las múltiples herramientas y procesos requeridos para la transformación de los datos siguen acarreando las mismas problemáticas que ya tenía ETL en cuanto a la velocidad del proceso, la cantidad de recursos necesarios y su coste y la escasez de escalabilidad.
¿Problema resuelto?
Para que ELT sustituya definitivamente ETL, las herramientas ELT tendrían que evolucionar. En cuanto a su evolución, se espera que en un futuro próximo estas herramientas incluyan capacidades de data governance y vayan resolviendo progresivamente los inconvenientes que aún plantean. Forbes plantea una solución que vuelve a suponer un giro argumental en la historia de la extracción, transformación y almacenamiento de los datos: EL+T.