¿Qué es y cómo funciona un data warehouse, en qué se diferencia del data lake y cómo es su arquitectura? ¡Te lo explicamos! | Data Warehouse con Bismart
Los conceptes data warehouse y data lake se suelen confundir. Sin embargo, estos dos tipos de almacenamiento de datos son mucho más diferentes de lo que puede parecer a simple vista. De hecho, lo único que tienen en común es que contienen grandes cantidades de datos.
¿Qué es un data warehouse?
Un data warehouse (almacén de datos, en español) es una infraestructura de almacenamiento de datos utilizada para almacenar, organizar y analizar grandes volúmenes de datos estructurados —en ocasiones también datos semiestructurados y no estructurados—. Estos datos pueden provenir de de diversas fuentes dentro de una organización, como bases de datos operativas, sistemas de gestión de relaciones con los clientes (CRM), sistemas de gestión de recursos empresariales (ERP) y otras fuentes.
El objetivo principal de un data warehouse es proporcionar un entorno centralizado para la toma de decisiones empresariales al permitir a las organizaciones consolidar datos de diferentes fuentes y analizarlos para obtener perspectivas significativas y oportunidades de negocio. Para lograr esto, los datos se transforman y se almacenan en un formato optimizado para el análisis, lo que facilita la consulta y el reporting.
El concepto de 'data warehouse' está estrechamente ligado a la toma de decisiones basada en datos y al aprovechamiento de información corporativa desde su origen. Este tipo de almacén de datos está especialmente diseñado para satisfacer las necesidades de inteligencia empresarial y análisis de datos, y a menudo se denomina Enterprise Data Warehouse (EDW) por esta razón.
Para ser más específicos, un data warehouse puede definirse como una arquitectura de almacenamiento e integración de datos que facilita la organización, transformación, comprensión y gestión de los datos. Además, permite aprovechar estos datos para tomar decisiones empresariales más informadas. La creación y el desarrollo de esta arquitectura, junto con las operaciones asociadas, se conocen como 'data warehousing'. Este término se refiere al proceso de recopilación, integración y organización de datos en un data warehouse.
A diferencia de otras bases de datos, el objetivo principal de un data warehouse es transformar datos brutos en perspicacias empresariales y facilitar el acceso a estos datos por parte de los usuarios de la empresa de manera rápida y eficiente.
Un data warehouse típicamente se complementa herramientas y tecnologías para la extracción, transformación y carga (ETL) de los datos, así como plataformas para el análisis y la visualización de datos. Utiliza técnicas como la indexación, la partición y la optimización de consultas para garantizar que las consultas analíticas sean rápidas y eficientes, incluso cuando se trabaja con grandes volúmenes de datos.
En resumen, un data warehouse es un componente fundamental en el ámbito de la inteligencia empresarial, ya que ayuda a las organizaciones a tomar decisiones informadas basadas en análisis de datos precisos y relevantes.
- Si tu empresa aún no cuenta con una estrategia de datos bien planteada, descárgate nuestro e-book gratuito con el que aprenderás los pasos y requisitos esenciales para consolidar una estrategia de datos que te permita aprovechar el valor empresarial de los datos.

¿Cómo funciona un data warehouse?
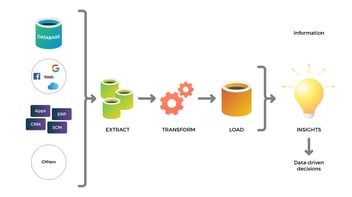
Un data warehouse funciona mediante un proceso sistemático que involucra la extracción, transformación, carga (ETL) y análisis de datos.
Un data warehouse suele ser el almacén de datos central de una organización. Después de extraer datos de sus fuentes originales e integrarlos en el data warehouse, estos son procesados, transformados y organizados en vistas y tablas de dimensiones o hechos. El método comúnmente utilizado para este propósito es el proceso ETL (Extract, Transform and Load) o, más recientemente, ELT (Extract, Load, and Transform).
Una vez que los datos han sido transformados y organizados, los usuarios pueden acceder a ellos a través de SQL, herramientas de inteligencia empresarial como Power BI, plataformas de gestión de clientes como un CRM, entre otras opciones.
A continuación, detallamos cómo funciona un data warehouse:
-
Extracción (Extract): Los datos se extraen de diversas fuentes dentro de una organización, como bases de datos operativas, sistemas CRM, ERP y otros sistemas de información. Estos datos pueden ser de diferentes tipos, como datos transaccionales, datos de clientes, datos de ventas, etc.
-
Transformación (Transform): Una vez que los datos se han extraído, pasan por un proceso de transformación. Durante esta etapa, los datos se limpian y se transforman en un formato estándar. Esto implica corregir errores, eliminar duplicados y convertir los datos a un formato consistente. Además, se pueden aplicar ciertas reglas de negocio y cálculos para crear datos agregados y derivados que sean útiles para el análisis.
-
Carga (Load): Los datos transformados se cargan en el data warehouse, donde se almacenan en estructuras optimizadas para el análisis. Los datos suelen organizarse en tablas y columnas para facilitar las consultas. Este proceso puede implicar la creación de índices para mejorar la velocidad de las consultas y la partición de datos para una gestión más eficiente.
-
Análisis (Analysis): Una vez que los datos están en el data warehouse, los usuarios pueden realizar análisis complejos y generar informes. Esto se hace utilizando herramientas de análisis y visualización que acceden a los datos del data warehouse y permiten a los usuarios hacer preguntas complejas y descubrir patrones y tendencias en los datos.
-
Presentación (Presentation): Los resultados del análisis se presentan a los usuarios en forma de informes, dashboards y visualizaciones interactivas. Estos informes ayudan a las organizaciones a tomar decisiones informadas basadas en los datos analizados.
Es importante destacar que el proceso de un data warehouse es continuo y repetitivo. Los datos se actualizan regularmente para asegurarse de que la información analizada esté siempre actualizada y sea relevante para la toma de decisiones empresariales.
Por otro lado, recientemente, algunas corporaciones están enfoando el proceso de extracción, transformación y carga de los datos (ETL) desde otra perspectiva, ELT, para ganar velocidad y flexibilidad.
¿Qué diferencias hay entre un data warehouse y data lake?
Los data lake y los data warehouse se utilizan de forma generalizada para el almacenaje de big data, pero, aunque ambos son almacenes de datos, estos no son términos intercambiables. Un data lake o "lago de datos" es un gran conjunto de datos en bruto, que todavía no tiene una finalidad definida. En cambio, un data warehouse o "almacén de datos" es un depósito de datos que ya están estructurados y filtrados y han sido procesados para un propósito concreto.
Es importante realizar la distinción, ya que los data lake y los data warehosue atienden a diferentes propósitos, por lo que requieren un enfoque diferente para ser optimizados adecuadamente.
Ambas herramientas son partes fundamentales de un proceso de integración de datos y suelen ser usadas en procesos ETL. La integración de datos es la base de cualquier estrategia de datos. Si los datos no están adecuadamente integrados, transformarlos en valor empresarial será altamente complejo.

Algunas de las diferencias principales entre un data warehouse y un data lake son la estructura de los datos, los métodos de procesamiento, en qué ámbito se utiliza y cuál es la finalidad de los datos.
Así, un data lake almacena datos sin procesar y que todavía no tienen una finalidad determinada. Sus usuarios finales son los científicos de datos y su accesibilidad es elevada. Además, en un data lake, justamente por esta fácil accesibilidad, se pueden actualizar los datos rápidamente.
Por su lado, un data warehouse cuenta con datos procesados y que ya se están usando, por lo que tienen una finalidad concreta. Los usuarios finales de un DW son, normalmente, empresarios y personas de negocios y es algo más complicado llevar a cabo cambios.
Data warehouse vs data lake: pros y contras
La diferencia que más aleja ambos conceptos es, seguramente, la estructura variable de los datos en bruto frente a los datos procesados. Como los data lake son los que suelen almacenar estos datos en bruto, su capacidad de almacenamiento debe ser más elevada que la de los data warehouse. Contar con estos datos en bruto tiene muchos beneficios, como poder analizarlos rápidamente y para cualquier propósito. Sin embargo, si no existen las medidas adecuadas de data quality y data governance, los data lakes pueden convertirse en una especie de contenedor intratable de datos del que se puede sacar poco valor.
Los beneficios de un data warehouse también son interesantes: como solamente almacenan datos procesados, ahorran mucho espacio de almacenamiento, lo cual se traduce en un ahorro de dinero. Además, al estar procesados, los datos son mucho más comprensibles y se vuelven accesibles para un público menos técnico.
Más allá de su propósito de almacenamiento, estos dos conceptos son bastante distintos. Los data lakes, por su contenido no estructurado, pueden ser complejos de navegar y requieren de un científico de datos, mientras que los data warehouse son más indicados para el uso en una empresa por parte de usuarios menos técnicos. Por todas estas diferencias, cada empresa debe valorar con los expertos cuál de los tipos le conviene más según los usos que le va a dar.
¿Cuándo usar un data warehouse en lugar de un data lake?
La decisión de usar un almacén de datos o un lago de datos depende de los requisitos específicos y los casos de uso de la organización. Tanto los almacenes de datos como los lagos de datos tienen fortalezas y debilidades distintas, por lo que es esencial comprender las características de cada uno y considerar las necesidades de gestión de datos de la organización. Aquí hay algunos escenarios en los que podrías elegir un almacén de datos en lugar de un lago de datos:
-
Datos Estructurados e Inteligencia Empresarial: Si tu organización trabaja principalmente con datos estructurados (por ejemplo, datos transaccionales, registros de ventas, datos financieros) y requiere capacidades de inteligencia empresarial y generación de informes, un almacén de datos es una elección adecuada. Los almacenes de datos están optimizados para manejar datos estructurados y están diseñados para admitir consultas analíticas complejas y generar informes precisos y consistentes.
-
Análisis de Datos Históricos: Los almacenes de datos son adecuados para almacenar datos históricos y mantener un registro de las transacciones comerciales a lo largo del tiempo. Proporcionan una vista variante en el tiempo de los datos, lo que permite el análisis de tendencias históricas y el seguimiento del rendimiento.
-
Esquema Bien Definido y Estable: Si tus datos tienen un esquema bien definido y estable, es decir, la estructura de los datos no cambia con frecuencia, un almacén de datos es ventajoso. Los almacenes de datos dependen de esquemas predefinidos para organizar los datos de manera eficiente, lo que los hace menos flexibles para adaptarse a cambios en el esquema sobre la marcha.
-
Datos Agregados y Resumidos: Si tus requisitos de informes y análisis implican datos agregados y resumidos (por ejemplo, totales de ventas, ingresos trimestrales, promedios anuales), un almacén de datos puede almacenar y gestionar datos preagregados de manera eficiente para un rendimiento de consulta más rápido.
-
Integración con Herramientas de BI Tradicionales: Los almacenes de datos son compatibles con herramientas tradicionales de inteligencia empresarial (BI) y plataformas de generación de informes. Si tu organización ya utiliza herramientas de BI populares como Tableau, Power BI o Qlik, integrar un almacén de datos en tu infraestructura existente es relativamente sencillo.
¿Cómo es la arquitectura de un data warehouse?
Como ya hemos avanzado, el gran aspecto diferenciador de un data warehouse es su arquitectura, que se estructura en diferentes capas que interactúan entre ellas y, a su vez, con los datos.
La arquitectura clásica de un data warehouse se compone de 3 capas:
-
Bronce: En la capa Bronce, también conocida como capa de Staging, los datos se extraen de sus fuentes originales, generalmente mediante scripts SQL.
-
Silver: En la capa Silver, también llamada Core, los datos de diversas fuentes originales se integran en el data warehouse. Después de almacenarlos, los datos se transforman y modelan, a menudo utilizando esquemas de estrella o copo de nieve. Luego, se transfieren a un servidor de procesamiento analítico en línea (OLAP). Una vez completada la transferencia, los datos se transforman nuevamente y se cargan en el data warehouse, donde están disponibles para análisis posterior y para respaldar la toma de decisiones.
Como ya hemos avanzado, estas dos capas iniciales suelen implementarse mediante un proceso ETL o ELT.
-
Oro: En la capa Oro, los datos son refinados para que sean accesibles para los usuarios. Esto implica organizarlos de manera que estén preparados para ser utilizados y exportados en diversas plataformas de inteligencia empresarial, generación de informes y visualización de datos, como Power BI y otras interfaces front-end.
Conclusión
En resumen, tanto el data warehouse como el data lake son herramientas fundamentales en el ámbito del almacenamiento de datos, pero difieren en su estructura, propósito y enfoque. Mientras que el data warehouse se centra en datos procesados y estructurados para la toma de decisiones empresariales, el data lake almacena datos en bruto sin una finalidad definida. Cada una de estas herramientas tiene sus ventajas y desventajas, por lo que es importante elegir la opción que mejor se adapte a las necesidades específicas de cada organización. Si bien el data warehouse es ideal para trabajar con datos estructurados y realizar análisis históricos, el data lake ofrece una mayor flexibilidad y accesibilidad para los científicos de datos. En última instancia, es esencial tener una estrategia de datos bien planteada y contar con expertos que puedan guiar en la elección y optimización del almacenamiento de datos.
No te pierdas nuestro e-book gratuito con las claves para diseñar y construir una estrategia de datos empresarial.