Discover what cloud data lake and cloud data lakehouse are, the new, more flexible, scalable and secure cloud infrastructures.
In today's digital age, efficient data management is essential for business success. As the amount of data generated by businesses continues to grow, effective data management becomes challenging. The new needs of businesses have led to the rise of new, more flexible, scalable and dynamic cloud infrastructures. We discuss cloud data lakes and cloud data lakehouses.
In the last ten years, most corporations have migrated their data to the cloud, moving to cloud services and platforms for the storage and management of their data assets. However, the world of cloud infrastructure is also evolving to adapt to companies' new data management needs.
Today, corporations require highly scalable cloud solutions capable of easily managing, integrating, analysing, sharing and protecting large volumes of data, in any format, without the need for the data to be previously modelled or stored in a predefined structure.
These new requirements have resulted in a shift from traditional cloud solutions, cloud data warehouses, to cloud data lakes. According to TDWI's 2021 report“Data Engineering and Open Data Lakes, the software industry is witnessing a massive shift from cloud data warehousing to cloud data lakes due to data lakes' greater flexibility.
The inherent flexibility of data lakes allows data professionals to adopt a "load the data first and ask questions later" approach, expanding possibilities in areas such as business intelligence, predictive analytics, app development and other data-driven initiatives. This shift represents a new era in data management, opening horizons in the age of agile, data-driven decision making.
What is a Cloud Data Lake?
A cloud data lake is a centralised data repository that allows organisations to store a large amount of structured, semi-structured and unstructured data at any scale. It is built on cloud storage services, which makes it highly scalable, cost-effective and capable of handling large volumes of data in multiple formats, such as text, images, videos, etc. Unlike data stored in a data warehouse, data stored in a data lake is typically processed using the ELT approach, so it is not modified or processed until it is needed. This provides greater flexibility to analytics and data science teams, who do not need to perform transformations on all data before storing it.
To explain it simply, let's take a look at data lake's name. As the name suggests, a data lake is like a large lake that collects information from many different places, like rivers flowing from many different sources. Unlike specialised data marts used for specific purposes, such as finance or human resources, where data is organised in advance to make it easier to search, a data lake seeks something more like the chaotic and diverse nature of rivers.
Rather than having a rigid, predefined schema like a traditional database, a data lake has the ability to store a wide variety of data as it is presented, without forcing it into a particular format. This approach allows the data lake to contain organised, semi-structured and unstructured data, thus providing more fertile ground for data experts to explore and analyse information more freely and creatively. Furthermore, while data processing in a data warehouse is usually based on the ETL approach, in a cloud data lake it is common to use an ELT approach.
In short, we could say that a cloud data lake is like a giant virtual lake that collects information from different sources, offering data analyusits a large and flexible area to explore and analyse data in a more open and unrestricted way.
Key features of a Cloud Data Lake:
- Scalability: Cloud data lakes can easily scale up or down based on data volume, ensuring they can accommodate growing data sets.
- Cost-effectiveness: Cloud data lakes leverage pay-as-you-go pricing models, allowing organisations to pay only for the storage and processing resources they use.
- Flexibility: They support a variety of data types and structures, allowing organisations to ingest and store raw data without the need for pre-defined schemas.
- Integration: Cloud data lakes integrate seamlessly with various analytics tools, machine learning frameworks and other cloud services, fostering an end-to-end data ecosystem.
- Analytic Capabilities: Users can perform advanced analytics, data exploration and machine learning directly on the data within the cloud data lake.
- Security and Compliance: Cloud providers offer robust security measures and compliance certifications to ensure the protection and privacy of data stored in the data lake.
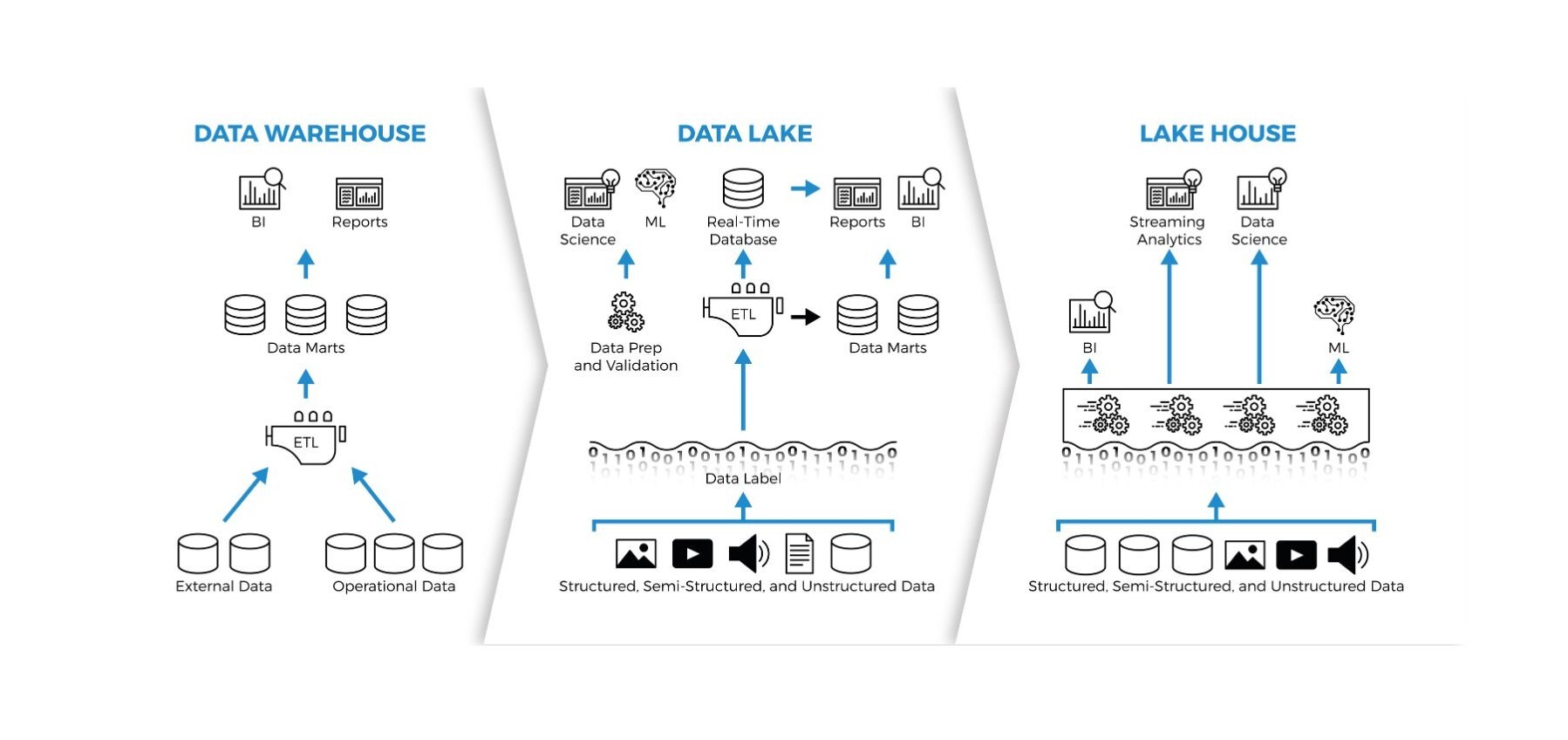
Cloud Data Warehouse vs Cloud Data Lake
The main difference between a data lake and a data warehouse is that a data warehouse is typically structured on a relational database —it stores structured data— and a data lake stores any type of data —structured, semi-structured or unstructured data—.
While cloud data warehouses are usually designed and modelled for a specific purpose, data lakes do not always have a pre-defined use case, which has contributed to the transformation from ETL to ELT. Their utility becomes evident later on, such as when analysts and data scientists perform data exploration for feature engineering, data visualisation, predictive modelling, etc.
What are the requirements for a cloud data lake?
To be a truly useful cloud integration solution, a data lake must provide a comprehensive set of tools that reveal the content within the data lake, identify data users and their usage patterns, and provide strong security capabilities.
Furthermore, it is essential that the cloud data lake has the ability to:
- Enable the storage of data in its original format.
- Facilitate users' self-exploration of data in an intuitive way.
- Automate routine data management tasks.
- Support a wide variety of use cases and workloads, such as modern data exchange.
- Integrate multiple data streams with different frequencies, without imposing excessive burdens on the data engineering teams responsible for building these data pipelines, and without storage or performance constraints.
To address these needs, software companies have invested in the creation of modern cloud data lakes: data repositories built in the cloud that allow structured, semi-structured and unstructured data to be organised in their original forms, either within the data lake itself or in an external object storage service.
With an appropriate software architecture, these data lakes provide almost unlimited capacity and scalability for the data storage and data processing required, making it easier to extract valuable information, derive value from the data and identify new business opportunities.
The era of the Data Lakehouse
Cloud Data Warehouse vs Data Lake vs Data Lakehouse
In the last few years, a growing trend has emerged that provides a new way to organise and manage data in the cloud: the Medallion Architecture. This new cloud architecture is not only aligned with companies' requirements for flexibility, but also stands out for its alignment with data quality initiatives.
The rise of the Medallion Architecture, in turn, has led to the emergence of a new cloud data repository known as data lakehouse, a new solution that combines the best features of the data warehouse and the data lake to address the limitations and complexities presented by these two approaches.
What is a Data Lakehouse?
A data lakehouse is an evolution of the concepts of data lake and data warehouse that seeks to combine the advantages of both approaches. In the Medallion Architecture, this approach is a comprehensive solution for managing data in all its diversity and providing a unified platform for diverse data processing and analysis needs.
Data lakehouses have become a possibility when technological advances have enabled software vendors to design an innovative system that combines the data structures and data management functions of a data warehouse with the type of low-cost object storage used in data lakes. This approach reimagines data warehousing in the modern world, taking advantage of the cost-effective and highly reliable storage offered by object stores.
The great advantage of a data lakehouse is that it can store any type of data, both structured and unstructured data, but integrating the data modelling functionalities of a data warehouse. The technology behind a data lakehouse allows queries and manipulations to be performed on the data in a fast and agile way as in a data warehouse.
A data lakehouse integrates the flexibility and massive storage capacity of a data lake with the organisational structure and analytical capabilities of a data warehouse. Basically, the great advantage of a data lakehouse is that it has the capacity to store structured, semi-structured and unstructured data. Thus, it allows data to be stored in its raw form, just as a data lake would, but also introduces organisational and structuring layers to facilitate efficient analysis and querying, capabilities more commonly associated with a data warehouse.
- Data warehouse: Stores structured data, so data scientists and analysts need to process and structure the data before storing it. This involves significant forethought in deciding what data is stored, how it will be structured and what its use cases will be.
- Data lake: Generally used to store semi-structured or unstructured data.
- Data Lakehouse: Built on a data lake infrastructure but integrates the functionalities of a data warehouse, so data scientists and analysts can store structured, semi-structured and unstructured data, avoiding the need to decide what to do with the data before storing it.
Data Governance in the Cloud
Despite all the advantages of the cloud data lakehouse mentioned before, we should remember that any type of data platform in the cloud requires the implementation of data governance policies to ensure the efficient use of data, its protection and compliance with data privacy and protection laws.
Defining data governance policies and measures also helps to ensure data quality by setting standards and avoiding inconsistencies that can lead to problems in the future.
Controlling access and roles in collaborative cloud environments is also essential to prevent unauthorised access and ensure data integrity.
Conclusion
In short, the evolution of cloud data infrastructures and data warehouses reflects the growing need for enterprises to manage data more efficiently and flexibly. From migrating data to the cloud to adopting approaches such as data lakes and data warehouses in the cloud, organisations are looking for solutions that meet their changing demands.
As a result, in recent years, a new way of storing data has emerged: the data lakehouse approach, which combines the characteristics of the data warehouse and the data lake. This hybrid approach enables more efficient management and deeper analysis of data, opening up new business opportunities and improving data-driven decision making.


