Big Data and the new demands that came with it have transformed ETL processes into a new perspective: ELT. Is ELT the future of ETL?
Big Data has transformed the way data is managed and stored, creating new demands for traditional data storage processes. Over time, requirements for higher volume and velocity have transformed ETL processes towards a new perspective: ELT.

As we already mentioned in the article "What Is ELT and How Is It Different From ETL?", in recent years ETL processes have been approached from a new perspective.
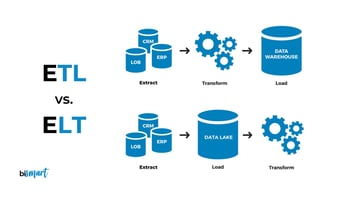
ETL —Extract, Transform & Load— is a data integration process that appeared in the 1970s and since then has been the most used method for integrating data from multiple data sources into a single data warehouse. In an ETL process, data is extracted from several data sources, transformed in a temporary database and finally loaded into the enterprise data warehouse. This method worked very well with data warehouses that were relational databases with predefined schemas. ETL has been the predominant process over the last 40 years, with a huge variety of ETL tools available in a multi-million dollar market.
However, new demands for volume, speed and validation have forced the emergence of a new approach to the process. ELT —Extract, Load & Transform— changes the order of an ETL process. With this new approach, data is extracted from the source data and loaded directly into the final data warehouse. Thus, unlike ETL, data transformations are performed on demand and in the final data warehouse.
But why did ELT happen? Is ETL dead?
Below we try to answer these questions.
From ETL to ELT or how Big Data has transformed the ETL process
The term 'Big Data' appeared for the first time in the late 1990s to put a name to the problems organisations were facing. Specifically, in 1997, a number of NASA researchers published an article in which it was stated that "the increase of data is becoming a problem for today's computer systems", which pushed technological progress towards platforms that could handle massive datasets. In 2001, the US company Gartner, published a paper —3D Data Management: Controlling Data Volume, Velocity and Variety— which mentioned Big Data's '3Vs' for the first time: volume, velocity and variety.
Big Data made the first challenges of the ETL process appear. The volume, velocity and variety demanded by Big Data compromised the performance of ETL tools, which were often unable to keep up with the pace of processing massive datasets due to lack of capacity and speed, as well as cost overruns.
The emergence of new data formats, data sources and data consolidation requirements also manifested the rigidity of the ETL process and changed the way data is consumed. The demand for more speed and variety meant that data consumers needed immediate access to raw data, rather than waiting for IT to transform and make it accessible.
On the other hand, Big Data also prompted the arrival of the data lake, a data warehouse that does not require a predefined schema, leading to more flexible storage schemes.
ETL tools, traditionally built with IT management in mind, are complicated to install, configure and manage. Furthermore, this technology conceives data transformation as a task for IT, making itinaccessible for data consumers who, according to ETL's logic, should only be able to access the final product stored in a standardised data warehouse.
As usual, the context precipitated innovation. ELT is seen as the natural evolution of ETL, reshaping the process and making it more suitable for Big Data and cloud services by providing greater flexibility. It also facilitates scalability, improves performance and speed and reduces costs.
However, ELT also has its own problems. Unlike ETL, ELT tools are designed to facilitate end consumers' access to data by allowing users to access data from any data source with a link. However, this can put data governance at risk.
The future of extraction, loading and transformation: ELT or ELT?
Claiming that ELT has definitively replaced ETL is unrealistic to say the least. For the time being, both processes coexist and, in fact, their combination already has a name: ETLT. Of course, getting rid of all the technologies and investments made in ETL to invest in ELT is not profitable for any corporation. On the other hand, companies that have not yet invested in either process should evaluate their data integration needs to decide which approach best fits with their business logic.
In addition to data governance, ELT also has other issues.
Despite optimising both E and L, ELT still falls short on the T. Today, data analytics plays a fundamental role in business. Despite the efforts of this new approach, data analysis, based on data transformation, has not been simplified and remains a task for the IT department, especially engineers and data scientists. Also, transforming raw data into assets ready to be used still requires complex tools and processes that data consumers clearly do not have the capacity to deal with. On the other hand, the multiple tools and processes required for data transformation still present the same issues that ETL had in terms of speed, scalability and the amount of resources required and their cost.
Problem solved?
For ELT to definitively replace ETL, ELT tools would have to evolve. In terms of their evolution, it is expected that in the near future such tools will include data governance capabilities and will progressively resolve the inconveniences they still have. Forbes suggests a solution that once again represents a turning point in the history of data extraction, transformation and storage: EL+T.