A data lakehouse combines the best of data lakes and data warehouses. Explore its architecture, benefits, and key cloud trends.
For a long time, companies stored their information in data warehouses: large repositories designed to organize data into well-structured tables and answer questions through SQL queries. They are highly useful, but also expensive and not very practical when it came to handling more modern types of data, such as documents, images, or information in less rigid formats.
To address this gap, data lakes emerged: more affordable and flexible repositories capable of storing any kind of data in its raw form. However, they came with a major drawback: the lack of clear organizational rules and governance mechanisms. Over time, this often led to declining data quality and made it harder to find and access the right information.
As a response to these limitations, a new architecture has been introduced: the data lakehouse, which combines the best of both worlds. It offers the flexibility and low cost of a data lake, while also providing the structure, governance and reliability of a data warehouse.
In this article, we take a closer look at what a lakehouse is, its main advantages and how it fits into a modern data strategy. We’ll also explore the latest trends that are shaping the evolution of this approach.
What Is a Data Lakehouse?
A Data Lakehouse is a flexible data architecture that combines the agility of a data lake with the analytical capabilities and structured approach of a data warehouse.
A fusion of two approaches
- From the data lake, it inherits the ability to store massive volumes of raw information of any kind: structured data (tables), semi-structured data (logs, JSON), or unstructured data (images, videos, IoT sensor streams).
- From the data warehouse, it incorporates advanced tools to organize that data, query it efficiently, and leverage it for business intelligence projects.
In other words, a data lakehouse lets you store data in its native form—without having to transform it upfront—while also providing the structure and speed needed for fast, reliable analysis.
The Value of a Unified System
The main goal of a data lakehouse is to bring together, in a single platform, the scale and low cost of a data lake with the organization, data governance, and performance of a data warehouse. This solves a very common challenge: data fragmentation.
In traditional two-tier architectures (lake + warehouse), data often had to be duplicated and transformed multiple times, increasing costs and causing delays. With a lakehouse:
- Open and cost-effective formats such as Parquet, ORC, or Delta are combined with the reliability of warehouse-style transactions.
- A single repository centralizes all data sources, eliminating repetitive migrations and ensuring that information is always up to date.
- Next-generation query engines enable high-performance SQL execution, supported by metadata layers that index files and guarantee ACID transactions.
- Data science teams can directly access the files to train machine learning models with tools like Spark, pandas, or TensorFlow.
A Single Source of Truth
In practice, the data lakehouse becomes the single source of truth within an organization: it breaks down silos, eliminates redundant copies, and allows both Big Data projects and business intelligence initiatives to coexist on the same platform.
This means that a wide variety of workloads can run on a single system: from BI reporting to AI model training and real-time data analytics.
The Architecture of a Lakehouse
Key Components
- Low-cost storage. Built on object storage (Azure Blob, Amazon S3, Google Cloud Storage) for raw data.
-
Metadata layer. Technologies like Delta Lake track the files that make up each table, enable ACID transactions, ensure version control, and validate schemas.
-
Query engine. Modern SQL engines optimize access to lakehouse data through caching, indexing, vectorized execution, and data ordering.
-
Governance layer. Defines who can access specific data, supports auditing, and ensures regulatory compliance.
-
Access interfaces. BI tools (such as Power BI) connect through SQL endpoints, while data scientists can use Spark, pandas, or TensorFlow APIs.
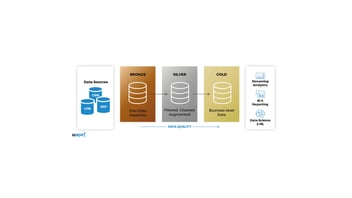
Medallion Architecture: Bronze, Silver, and Gold
One of the best practices within a data lakehouse is to apply a layered quality design known as the Medallion Architecture (also called multi-hop architecture).
Originally proposed by Databricks, the Medallion Architecture is an approach that logically organizes data in a lakehouse into three sequential layers —Bronze, Silver, and Gold—promoting continuous improvement in data quality as it moves from its raw state to business-ready information.
In other words, each Medallion layer represents a stage of data refinement, with validations and transformations that ensure increasing levels of integrity and usability.
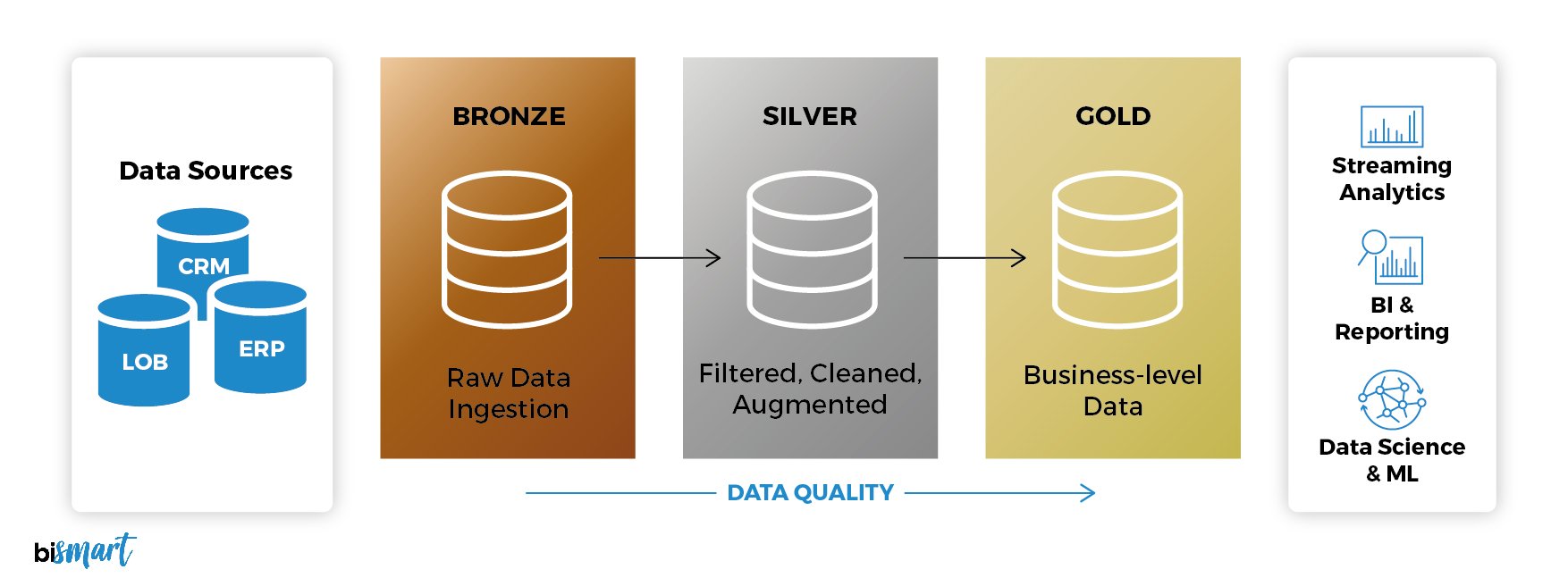
- Bronze Layer (Raw Data): In this initial layer, data is stored exactly as it arrives, in its original format, along with metadata that records its source and time of ingestion. Its main purpose is to preserve a complete, historical, and auditable copy of everything that enters the system. This makes it particularly useful for tasks such as change data capture or reprocessing data in the future if needed.
- Silver Layer (Validated Data): Here, the data from the Bronze layer is cleaned, refined, and standardized to provide a unified business view. At this stage, for example, duplicate records in customer or product catalogs are removed, and consistent rules are applied to ensure accuracy. This layer involves light transformations and models that guarantee data coherence.
- Gold Layer (Curated Data): In the final stage, the data is business-ready. It is organized into models optimized for specific use cases such as sales, marketing, or product recommendations. Strict quality rules are applied, and specialized data marts are built, enabling business teams to access direct, actionable insights.
This layered pattern brings a major advantage: it ensures data traceability. Any table or model can always be reconstructed starting from the original information stored in Bronze. In this way, it combines the flexibility of raw data with the reliability of validated and curated versions prepared for decision-making.
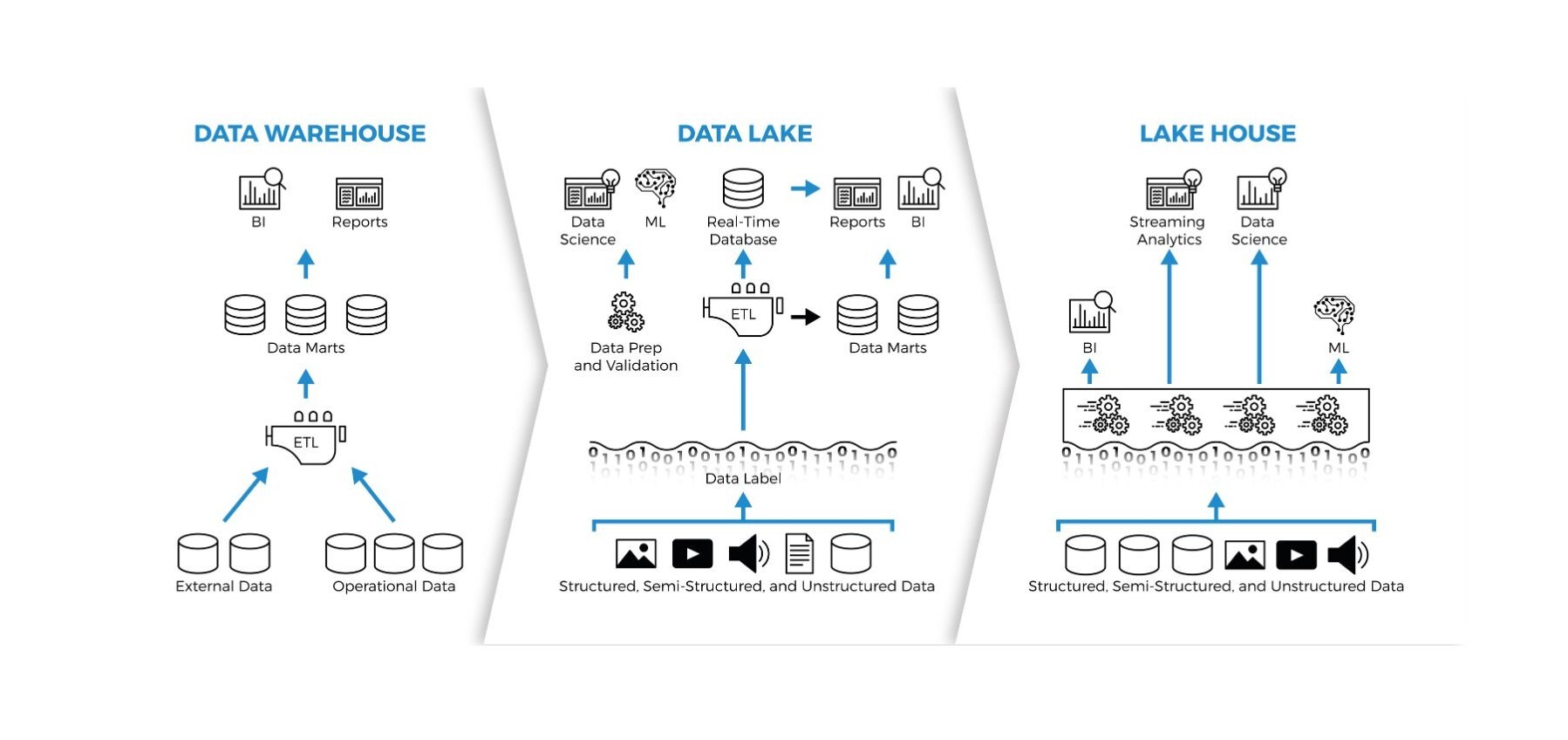
Data Warehouse vs. Data Lake vs. Data Lakehouse
To understand what a data lakehouse brings to the table, it’s useful to compare it with its predecessors: the data warehouse and the data lake. Each was created to solve a specific need, but each also comes with its limitations.
Comparison: Data Warehouse vs. Data Lake vs. Data Lakehouse
| Technology | Main Use Case | Key Advantages | Limitations |
|---|---|---|---|
| Data Warehouse | Analyze structured data and support business intelligence (BI). | High performance for SQL queries; high-quality data; reliable ACID transactions. | Expensive; difficult to scale; limited to highly structured data. |
| Data Lake | Store large volumes of raw data (structured, semi-structured, and unstructured). | Scalable and cost-effective; highly flexible to store any type of format. | No reliable transactions; lacks governance; slower access. |
| Data Lakehouse | Unified platform that supports analytics, operations, and AI applications. | Combines the best of both worlds: low-cost storage with data management, transactions, and high performance. Eliminates redundant ETL processes and enables machine learning. | Still-evolving technology; requires adopting new patterns (such as the Medallion model) and specialized tools. |
Data Lakehouse in Microsoft Fabric
In the cloud, the lakehouse approach significantly simplifies data workflows. Teams no longer need to maintain two separate infrastructures —one for storing raw data and another for analyzing it—. With a lakehouse, data only needs to be ingested once, enabling multiple use cases: from BI dashboards to predictive analytics, machine learning, and artificial intelligence projects.
The lakehouse concept was initially championed by pioneering companies like Databricks, and major cloud providers soon integrated it into their services. Among them, Microsoft stands out with Microsoft Fabric, which includes a native Lakehouse component designed to deliver unified analytics on a single platform.
The Data Lakehouse in Microsoft Fabric represents the natural evolution of cloud data management. Thanks to this architecture, workflows become simpler, more flexible, and more efficient—allowing organizations to respond quickly to today’s needs and accelerate innovation.
SQL Analytics Endpoint in Microsoft Fabric
One of the most practical advantages of creating a lakehouse in Microsoft Fabric is that it automatically generates an SQL analytics endpoint. This feature provides a read-only relational interface over Delta tables, enabling users to:
- Run T-SQL queries with ease.
- Build semantic models directly for Power BI.
In practice, this means that business users can access data through familiar tools, without having to deal with the technical complexity behind the lakehouse architecture.
Key Benefits of a Data Lakehouse
Adopting a data lakehouse brings significant advantages for organizations looking to simplify data management and extract more value from their information. Some of the most notable benefits include:
1. Unified, Duplicate-Free Data
A lakehouse consolidates all information into a single platform, eliminating silos and unnecessary copies. This ensures a single “source of truth”, allowing all teams to work with the same up-to-date and reliable data.
2. Cost Reduction
It leverages cost-effective cloud storage (such as AWS S3 or Azure Data Lake) and removes the need to maintain separate infrastructures for storage and analytics. As a result, costs are significantly lower compared to traditional data warehouses.
3. Support for All Types of Analytics
A well-designed lakehouse supports multiple use cases: from business reporting and visualization to data science, machine learning, and advanced analytics. Everything happens on the same data, without having to move it across systems.
4. Stronger Governance and Data Quality
Unlike traditional data lakes, the lakehouse incorporates governance and organizational mechanisms. Data is validated against policies and rules before being considered trusted, preventing the platform from turning into a chaotic repository.
5. Scalability and High Performance
In the cloud, the lakehouse separates storage from compute. This allows flexible scaling, with different engines (SQL, Spark, etc.) working in parallel on the same data—without duplication or bottlenecks.
6. Real-Time Data
The lakehouse is designed to handle streaming data flows from IoT sensors, applications, or activity logs. This enables real-time analytics and responses, which are critical in industries that demand immediate access to information.
Future Trends: Toward Lakehouse 2.0 and Beyond
The world of data is constantly evolving. Just as traditional data warehouses gave way to data lakehouses, we are now seeing the first steps toward a new generation known as “Lakehouse 2.0.” This evolution aims to overcome the limitations of the first wave of lakehouses and adapt to today’s challenges: greater openness, modularity, and real-time analytics.
More Open and Flexible Ecosystems
One of the key trends is the rise of open table formats such as Apache Iceberg, Delta Lake, and Apache Hudi. These formats allow different engines and platforms to work with the same data without being tied to a single vendor. The result is a more flexible ecosystem, where storage and compute are decoupled, and organizations are free to choose the tools that best fit their needs.
Integrated Semantic Layers
Another key innovation is the incorporation of unified semantic models directly within the lakehouse. This means that metrics, indicators, and business rules are no longer defined separately in each BI tool. Instead, the entire organization relies on a single centralized model, ensuring KPIs are always calculated consistently and avoiding unnecessary reprocessing.
Data Contracts and Cross-Team Trust
Lakehouse 2.0 also drives the concept of data contracts: formal agreements between data producers and data consumers. These contracts define the expected format, quality, and frequency of the data, fostering greater trust, transparency, and collaboration across teams.
Vendor Commitment and Open-Source Momentum
Major tech companies and the open-source community are already driving this new paradigm forward:
- Microsoft has launched Fabric, a platform that unifies data engineering, data warehousing, and data lakes into a single service, with the lakehouse as its central pillar.
- Databricks continues to evolve its Lakehouse Platform, adding unified catalogs (Unity Catalog), advanced governance tools, and machine learning capabilities built directly on the same data repository.
- Google offers BigLake, which combines the power of BigQuery with the flexibility of data lakes in a single unified layer.
- Even traditional database vendors are adapting their offerings to avoid being left behind.
Conclusion: Lakehouse as the Pillar of a Modern Data Strategy
The data lakehouse has established itself as the foundation of modern data architecture. Its ability to unify information from multiple sources, scale seamlessly in the cloud, and provide flexible access for diverse analytical use cases makes it a cornerstone in the era of Big Data and artificial intelligence.
When combined with approaches such as data mesh and practices like the Medallion Architecture, the lakehouse enables organizations to become truly data-driven, extracting value from their data more quickly, securely, and collaboratively.
For companies aiming to lead in the digital economy, investing in a data lakehouse strategy with strong practices in data quality and data governance is no longer optional. It is a strategic decision that makes all the difference. The key lies in turning data into a genuine competitive advantage and in communicating that value clearly and effectively, bridging the gap between technical vision and accessible language that resonates across every level of the organization.