Discover the 10 most widely used types of algorithms. Explore how these algorithms have transformed the way we process information and make decisions.
In today's digital age, the ubiquity of technology and the explosion of data have led to an increasing reliance on algorithms in a variety of fields. These intricate sets of instructions and rules define the core of artificial intelligence and machine learning, driving significant advances in complex problem solving and automated decision-making. In this vast algorithmic landscape, a fascinating variety of approaches unfolds, each designed to tackle different types of problems.
This article will dive into the fascinating world of algorithms, exploring their different categories and highlighting those that have emerged as the most prominent and widely used today. From classic algorithms that have withstood the test of time to more recent innovations that harness modern computational power, we will examine how these algorithms have radically transformed the way we process information and make decisions in an increasingly digitised world. Join us on this exploratory journey as we unravel the mysteries of algorithms, from their foundations to their most cutting-edge applications.
The 10 most used types of algorithms
The truth is that there are many, many types of algorithms and it is impossible to be familiar with all of them. However, here are a few of the most commonly used ones.
1. Sorting algorithm
A sorting algorithm is a set of instructions designed to arrange elements in a data set in a specific order. Sorting is fundamental to efficient data manipulation and is applied in a variety of areas, such as databases, search algorithms and information processing. The two most common sorting algorithms are:
- Quicksort: An efficient sorting algorithm that uses a "divide and conquer" strategy. It divides the data set into smaller subsets, sorts each subset and then combines the results.
- Mergesort: A sorting algorithm that also employs the "divide and conquer" strategy. It divides the set into halves, sorts each half, and then combines the sorted halves to obtain the final sorted set.
2. Search algorithms
A search algorithm is a set of instructions designed to find the location or determine the existence of a specific item within a data set. There are several search strategies, and the choice of algorithm depends on factors such as the structure of the data and the efficiency required. However, the two most commonly used search algorithms are:
- Linear Search: Examines each element in the dataset in sequence until the desired element is found or the end is reached. It is simple but can be inefficient on large datasets.
- Binary Search: Applicable only on ordered data sets. Repeatedly divides the set in half and compares the desired element with the element in the middle, thus reducing the search space.
Both sorting and search algorithms are fundamental and widely used in programming and efficiently solving problems related to data organisation and search. The choice of the appropriate algorithm depends on several factors, such as the size of the data set, the complexity of the problem and efficiency requirements.
3. Graph algorithms
A graph algorithm is based on rules designed to solve problems involving data structures called graphs. Graphs are abstract representations of relationships between objects and consist of nodes (or vertices) and edges (or arcs) connecting these nodes.
Graph algorithms are used to analyse and manipulate these structures in order to solve practical problems in various fields. Again, within the range of graph algorithms, there are many types of algorithms, the most important of which are:
- Breadth-first search (BFS): An algorithm that explores all nodes at the same depth before advancing to nodes at the next depth. It is useful for finding the shortest path in unweighted graphs.
- Dijkstra algorithm: Used to find the shortest path between a source node and all other nodes in a weighted graph with non-negative weights.
- Bellman-Ford algorithm: Similar to Dijkstra but can handle graphs with negative weighted edges. It is used to find the shortest path in graphs with variable costs.
- Kruskal algorithm: Used to find a minimum spanning tree in a weighted graph. This tree spans all the nodes of the graph and has the minimum sum of the edge weights.
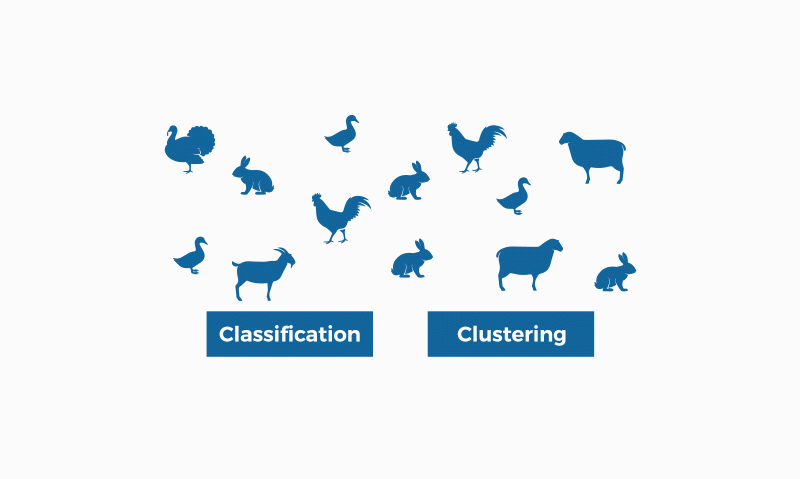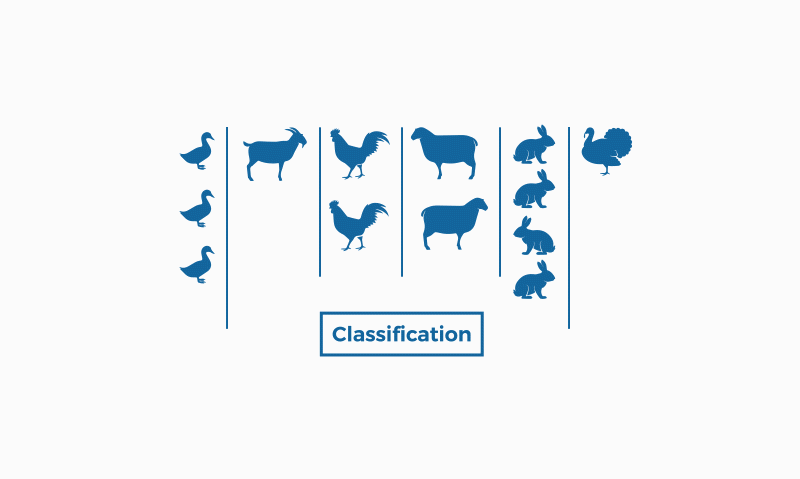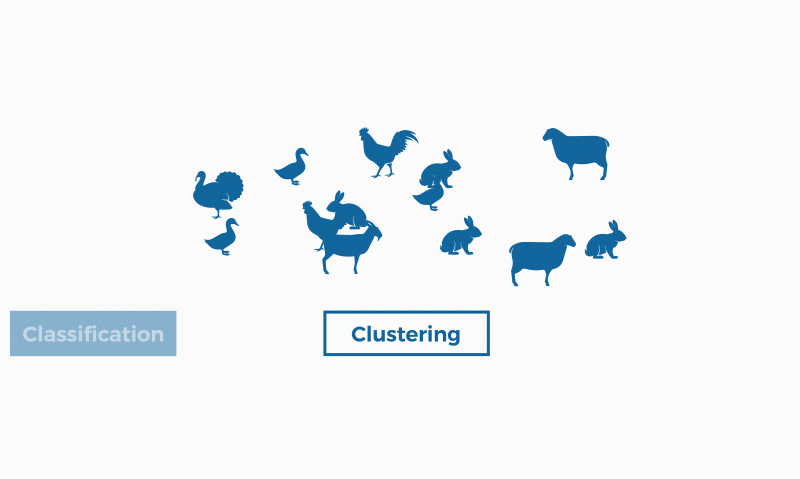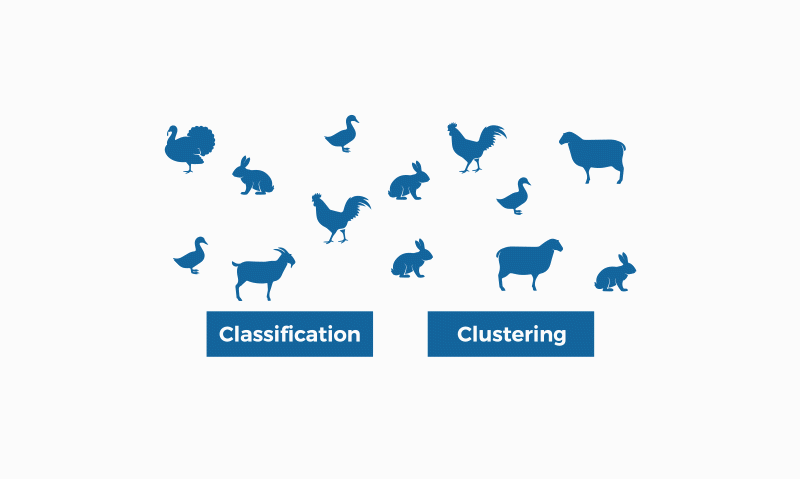
4. Classification algorithm
A classification algorithm is a set of instructions or rules designed to assign an object or instance to a specific category or class, based on its characteristics or attributes. These algorithms are widely used in machine learning and data mining to organise and label data automatically, enabling pattern identification and decision making.
The classification process involves training a model using a training dataset, where instances are provided along with their respective class labels. The model uses this information to learn patterns and relationships between features and classes. Once trained, the model can be used to classify new instances whose class labels are unknown.
Some common classification algorithms include:
- Logistic Regression: Despite its name, it is used for binary classification problems, assigning instances to one of two possible classes.
- Support Vector Machines (SVM): Searches for a hyperplane that maximises the margin between classes in a feature space.
- Decision Trees (explored in more depth below): Represent decisions in the form of a tree, iteratively dividing the data set into subsets.
- K-Nearest Neighbours (KNN): Classifies an instance according to the most classes of its k nearest neighbours in the feature space.
- Naive Bayes: Based on Bayes' theorem, assumes independence between features and assigns probabilities to classes.
- Neural Networks: Models inspired by the functioning of the brain, used for complex classification problems.
- Random Forest: An ensemble of decision trees that vote to determine the class of an instance.
- Gradient Boosting: Combines multiple weaker models to improve overall model accuracy.
The choice of classification algorithm depends on the nature of the problem, the size and quality of the data, as well as the specific requirements of the application context. Each algorithm has its own characteristics and performance in different situations, so proper selection is essential to achieve optimal results.
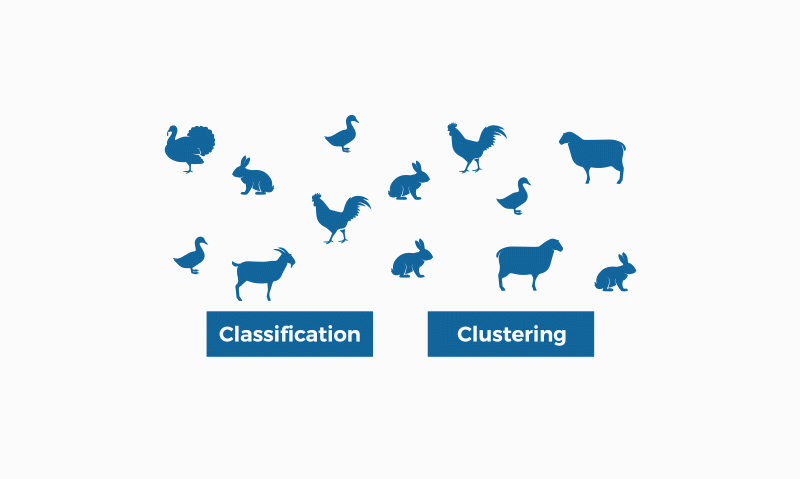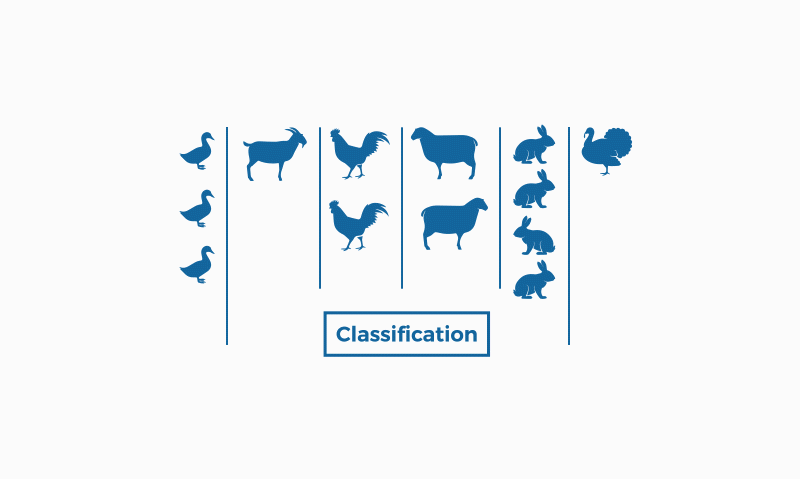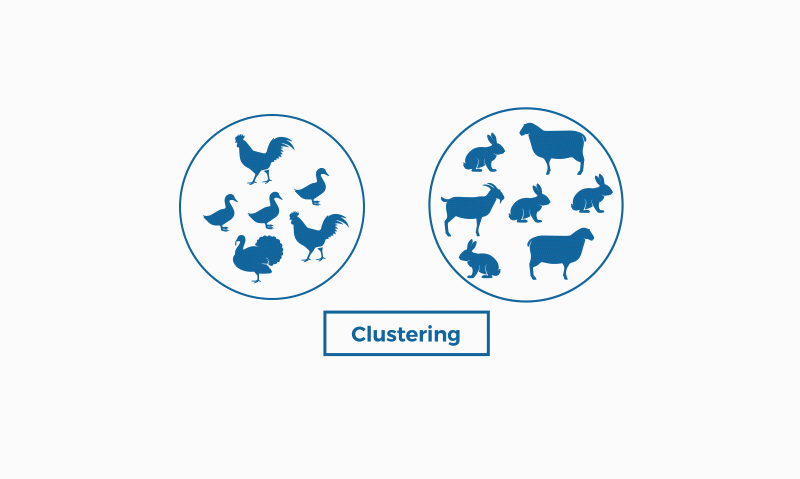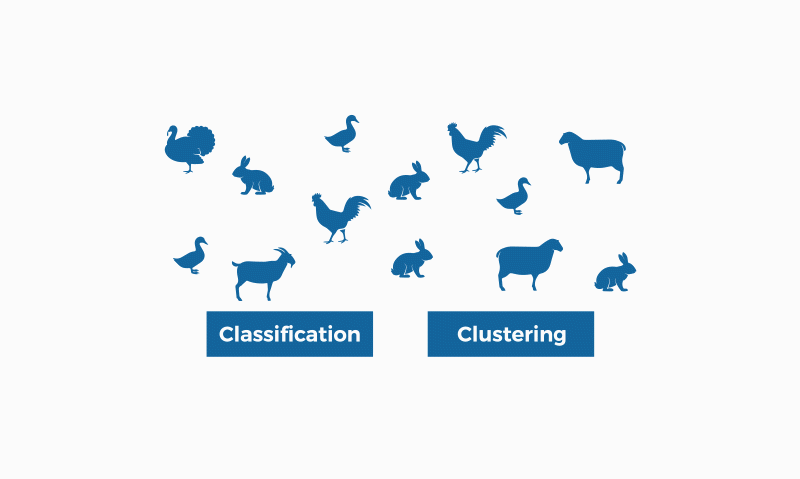
5. Regression algorithms
Regression algorithms are a set of techniques in machine learning and statistics used to model and analyse the relationship between variables. These algorithms are mainly applied in prediction problems for predictive analytics, where the objective is to predict the value of an output variable (or dependent variable) based on one or more input variables (or independent variables).
The main task of a regression model is to find a mathematical function that describes the relationship between the input variables and the output variable. The resulting function can be used to make predictions about future or unknown values of the output variable.
Some common regression algorithms include:
- Simple and Multiple Linear Regression: Simple linear regression models the relationship between two variables, while multiple linear regression models the relationship between more than two variables, considering multiple predictors.
- Polynomial Regression: This technique uses a polynomial equation to model non-linear relationships.
- K-Nearest Neighbors Regression (KNN): The algorithm predicts the output value based on the output values of the k nearest neighbors in the feature space.
- Support Vector Machines (SVM) for Regression: This algorithm finds a hyperplane in the feature space that best fits the data.
- Regression Trees: By using decision trees, this algorithm models non-linear relationships and segments the feature space into regions.
- Ridge and Lasso Regression: These are regularization techniques that help control model overfitting.
- Neural Networks for Regression: This algorithm employs neural network architectures to model complex relationships.
6. Decision tree algorithm
A decision tree algorithm is a supervised learning method used in the field of machine learning and artificial intelligence. It is designed to make decisions based on multiple conditions or features. Decision trees model decisions in the form of a tree, where each internal node represents a test on a feature, each branch represents the outcome of that test, and each leaf represents the final decision.
Key features of decision trees:
- Recursive Division: The tree is built recursively, partitioning the dataset into smaller subsets based on relevant features.
- Decision Criteria: At each node, a test is conducted on a specific feature, and the decision on which feature to choose and how to divide is made using a criterion that maximizes the purity of the resulting leaves.
- Classification or Regression: Decision trees can be utilized for both classification and regression problems. In classification, the leaves represent classes or categories, while in regression, the leaves contain numerical values.
- Interpretability: A key advantage of decision trees is their ability to be easily interpreted by humans. The tree provides a logical structure that can be visually understood.
7. Greedy' algorithm:
A greedy algorithm is an approach to algorithm design that makes local decisions at each step in the hope of arriving at a globally optimal solution. In other words, at each step, the algorithm selects the option that appears to be the best at the time, without considering the long-term consequences. The idea is to make decisions that appear to be the most beneficial at the present moment, without worrying about their future impact.
Key features of greedy algorithms:
- Greedy Choice: At each step, the algorithm makes the decision that appears to be the best at the time.
- No Backtracking: Once a decision is made, it is not reviewed or changed at later stages.
- Global Optimisation Expectancy: Despite making local decisions, the sequence of decisions is expected to lead to a globally optimal solution or at least an acceptable solution.
Greedy algorithms are effective in situations where the locally optimal choice also leads to a globally optimal or near-optimal solution. However, they do not always guarantee the best solution in all cases, so their applicability depends on the specific problem being addressed.
8. Brute-force algorithm
A brute-force algorithm is an algorithm whose essence is based on trying all possible solutions and verifying which one is correct. This exhaustive method is simple and guarantees to find the optimal solution to a problem, but is often inefficient due to the large number of combinations to consider, especially when the size of the problem increases.
Key features of brute force algorithms:
- Exhaustive Exploration: This type of algorithm considers all possible combinations to find the solution.
- No Optimisation Strategy: They do not rely on intelligent strategies to reduce the search space.
- Guaranteed Optimal Solution: Because they examine all possibilities, brute-force algorithms are guaranteed to find the optimal solution if it exists.
While brute-force algorithms can be effective for small problems or when there is no known more efficient solution, their execution time can become impractical (time complexity) as the problem size increases. In many cases, more specialised and efficient algorithms are sought to address specific problems.
9. Backtracking algorithm
A backtracking algorithm tries to search for all possible solutions to a problem by systematically exploring all available options. This approach is based on the principle of trial and error, where the algorithm moves forward to try a solution, but backtracks when it realises that the partial solution cannot lead to a valid solution.
Key features of backtracking algorithms:
- Systematic Exploration: The algorithm systematically tests all possible solutions, building and unbuilding partial solutions as needed.
- Sequential Decisions: It makes sequential decisions to build a solution, backtracking when it encounters an invalid state.
- No Guarantee of Optimal Solution: Although it may find a solution, it does not guarantee the optimal solution.
The success of a backtracking algorithm depends on efficient decision-making to avoid unnecessarily exploring certain paths. In some cases, additional techniques, such as pruning, are used to reduce the search for solutions. Efficient implementation and appropriate choice of strategies are essential to effectively tackle problems with backtracking algorithms.
10. Dynamic programming algorithms
A dynamic programming algorithm is a type of algorithm designed to divide a problem into smaller subproblems and solve each of the subproblems first. The solutions found are stored to avoid rework. This technique is especially useful when a problem can be decomposed into overlapping subproblems or subproblems that share common solutions.
Key features of dynamic programming:
- Optimal Substructure: The overall problem can be solved by combining optimal solutions of smaller subproblems.
- Subproblem Overlap: Subproblems share common solutions, and dynamic programming avoids recalculating solutions for each subproblem by storing and reusing already calculated results.
Fundamental steps in a dynamic programming algorithm:
- Problem Definition: Formulate the problem in terms of smaller subproblems.
- Subproblem Identification: Identify subproblems to be solved and combined to solve the overall problem.
- Recursive Equation Definition: Develop a recursive equation that relates the solution of the original problem to the solutions of its subproblems.
- Order of Solving: Determine the order in which the subproblems are solved to ensure that the necessary solutions are available when required.
- Results Storage: Storing the results of solved subproblems in a data structure (often a table or matrix) for reuse.
Other types of algorithms
Encryption algorithms
Beyond the algorithms mentioned above, it is also essential to know about encryption algorithms, which convert the data in a file in such a way that it cannot be retrieved without the corresponding encryption key. These algorithms are the basis of online security.
Conclusion
In this blog post, we have explored a variety of algorithms used in machine learning and artificial intelligence. We have learned about algorithms such as Polynomial Regression, KNN, SVM, Regression Trees, Ridge and Lasso Regression, Neural Networks, as well as the Decision Tree Algorithm, Greedy Algorithms, Brute Force Algorithms, Backtracking Algorithms, and Dynamic Programming Algorithms. Each of these algorithms has its own characteristics and specific applications. Additionally, we have mentioned the importance of encryption algorithms in online security. If you are interested in learning more about these algorithms and how they are applied in the real world, I encourage you to continue researching and delving into each of them. The world of artificial intelligence and machine learning is fascinating and constantly evolving, so don't get left behind!


