Classification and clustering are two pattern identifying methods in machine learning. In this post we explain which are their differences.
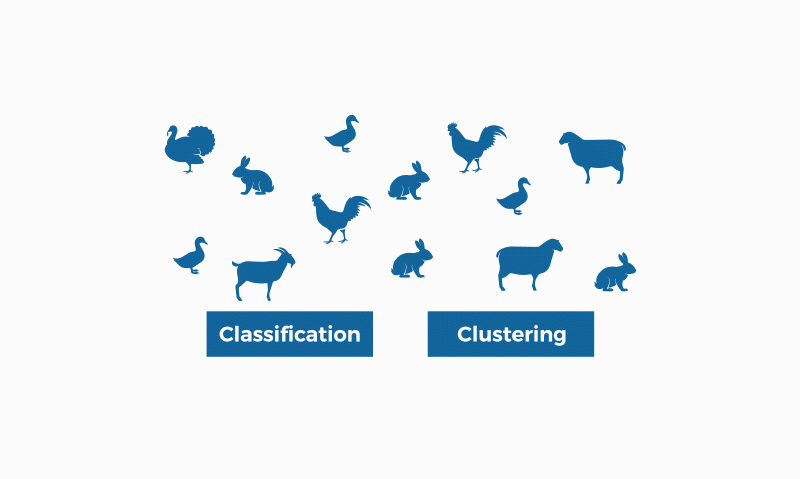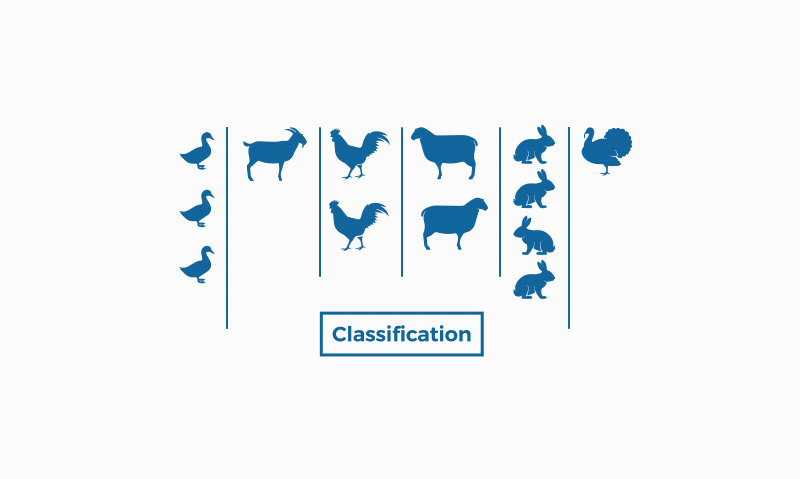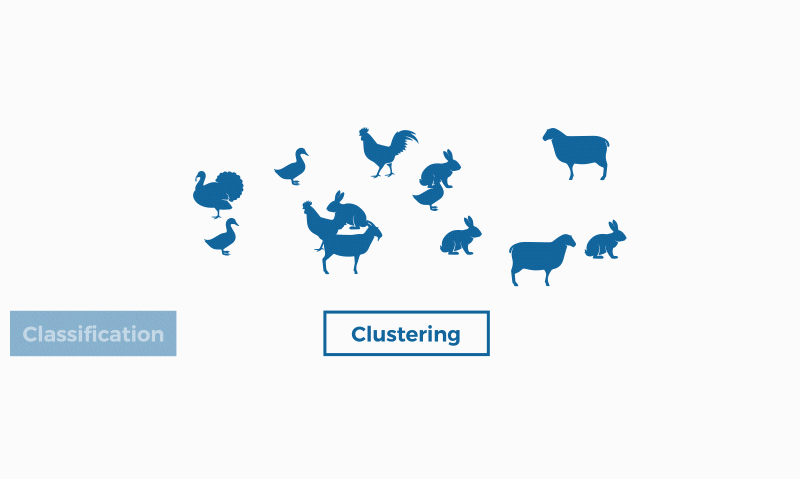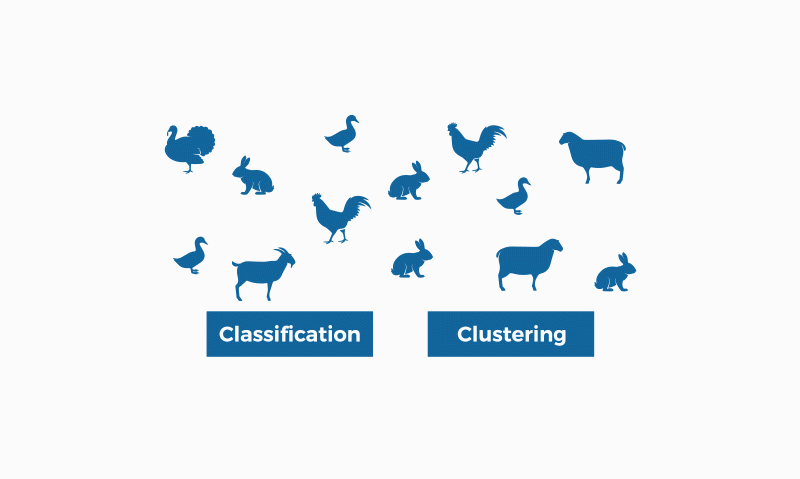
Classification and clustering are two methods of pattern identification used in machine learning. Although both techniques have certain similarities, the difference lies in the fact that classification uses predefined classes in which objects are assigned, while clustering identifies similarities between objects, which it groups according to those characteristics in common and which differentiate them from other groups of objects. These groups are known as "clusters".
In the field of machine learning (a form of artificial intelligence), clustering is framed in unsupervised learning; that is, for this type of algorithm we only have one set of input data (not labelled), about which we must obtain information, without previously knowing what the output will be.
What is clustering?
Clustering is used in projects for companies that want to find common aspects within their customers to apply customer segmentation, create customer journey maps or find groups and focus products or services. Thus, if a significant percentage of customers have certain aspects in common (age, type of family, etc.) the company can justify a particular campaign, service or product. Clustering is also useful to obtain general insights and information.
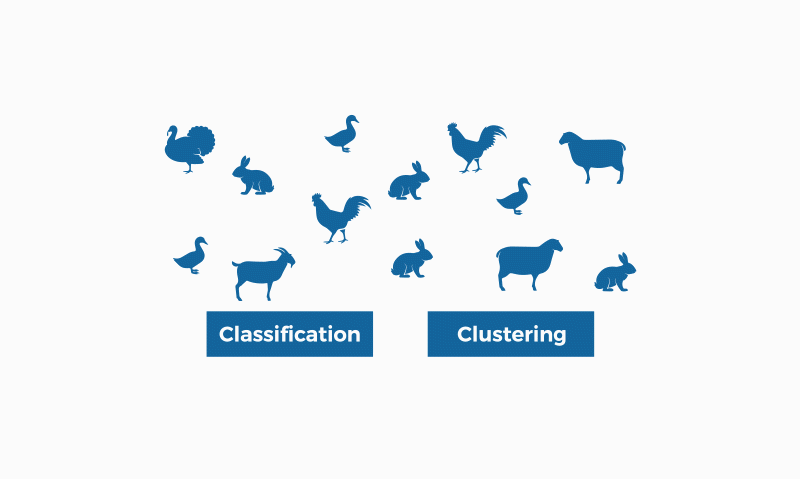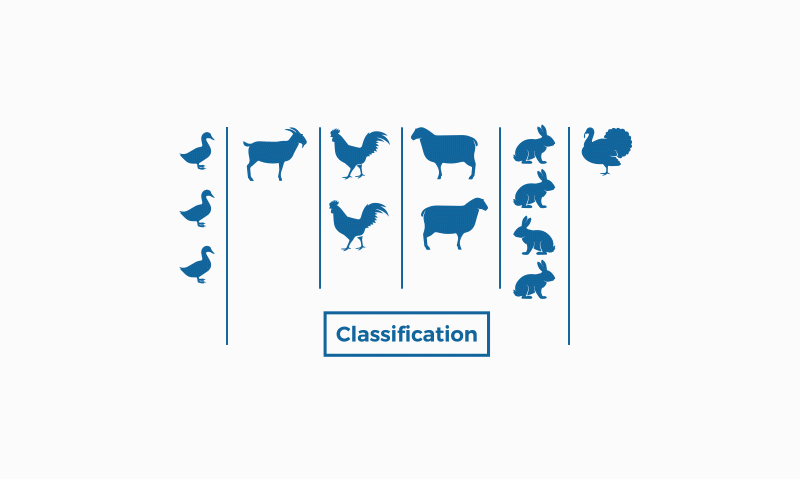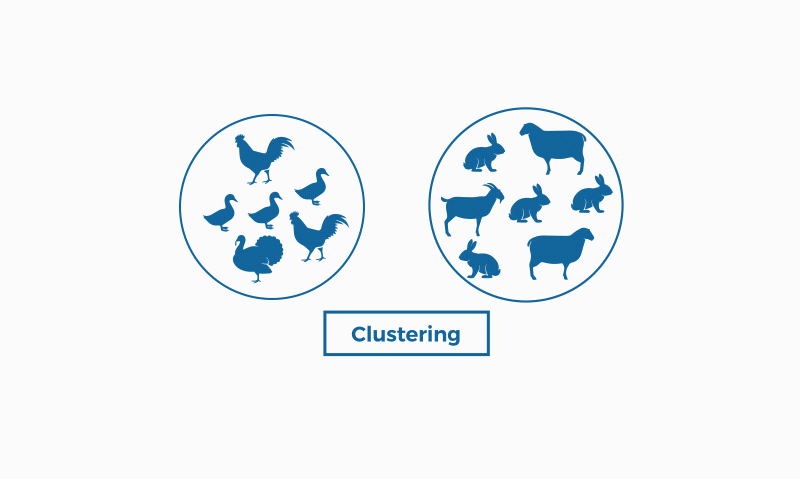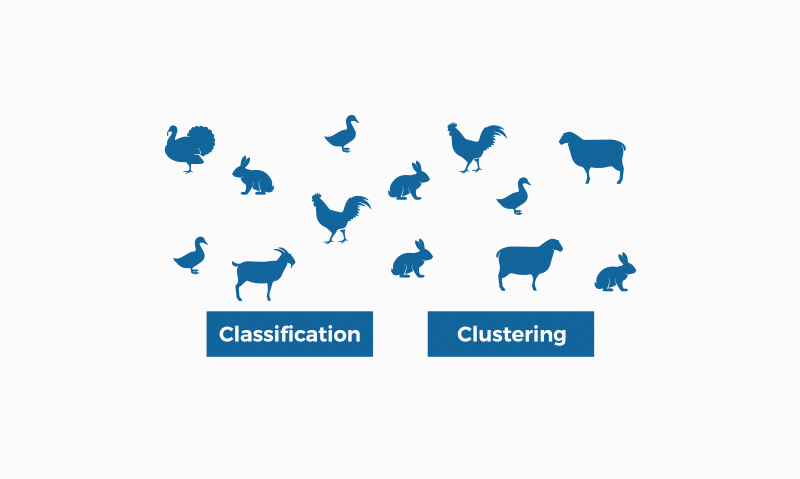
What is classification?
On the other hand, classification belongs to supervised learning, which means that we know the input data (labeled in this case) and we know the possible output of the algorithm. There is the binary classification that responds to problems with categorical answers (such as "yes" and "no", for example), and the multiclassification, for problems where we find more than two classes, responding to more open answers such as "great", "regular" and "insufficient".
Classification is used in many fields, such as biology or in the Dewey decimal classification for books, in the detection of spam in e-mails...
At Bismart, Microsoft's Power BI partners, we use classification and clustering in our projects, which are framed in many different sectors. For example, in the social services industry, we have used clustering to identify population groups that use specific social services. From social services data, we have been able to identify or cluster groups of people who use similar services according to their attributes (number of people in their charge, degree of dependency, marital status...). Thus, we have been able to detect what type of service a new user of social services will need beforehand by comparing their attributes with those of the clusters.
Classification is used when you need to know users or customers to decide which products or campaigns will be launched in the future. For example, at Bismart we developed a project for the insurance industry in which the client needed to classify customers according to accident claims, so that the policy could be classified according to the number of claims predicted. Thus, the company can choose the costumers with the lowest number of claims.
Classification vs. Clustering
What is the difference between classification and clustering algorithms?
Both classification and clustering are techniques used in machine learning for pattern identification. While they both involve grouping objects based on similarities, there is a key difference between the two.
Classification involves assigning objects to predefined classes based on their characteristics. For example, in the insurance industry, customers can be classified based on their accident claims to determine the appropriate policy for them.
On the other hand, clustering focuses on identifying similarities between objects and grouping them accordingly. This can be useful in various scenarios such as customer segmentation, where businesses can tailor their marketing campaigns and services to specific customer groups based on common characteristics. Additionally, clustering algorithms are used in fraud detection, recommendation systems, and even in the creation of original series by platforms like Netflix. In conclusion, both classification and clustering offer valuable insights and can be powerful tools for businesses looking to improve their operations and customer relations.
Examples of clustering algorithms
Netflix
A well-known application of clustering algorithms are Netflix recommendation systems. Although the company is quite discreet with its algorithms, it is confirmed that there are about 2,000 clusters or communities that have common audiovisual tastes. Cluster 290 is the one that includes people who like the series "Lost", "Black Mirror" and "Groundhog Day". Netflix uses these clusters to refine its knowledge of the tastes of viewers and thus make better decisions in the creation of new original series.
Customer segmentation
One common use case for clustering is customer segmentation in companies. By clustering customers based on common characteristics such as age, family type, or purchasing behavior, businesses can tailor their marketing campaigns, services, and products to specific customer groups. This not only helps in improving customer satisfaction but also allows companies to make informed decisions based on the insights gathered from clustering.
Examples of classification algorithms
Fraud Detection
Classification is commonly used in the financial sector to guarantee data security. In the era of online transactions where the use of cash has decreased markedly, it is necessary to determine whether movements made through cards are safe. Entities can classify transactions as correct or fraudulent using historical data on customer behavior to detect fraud very accurately.
Would you be interested in improving your business processes and customer relations with classification and clustering? We can help you!