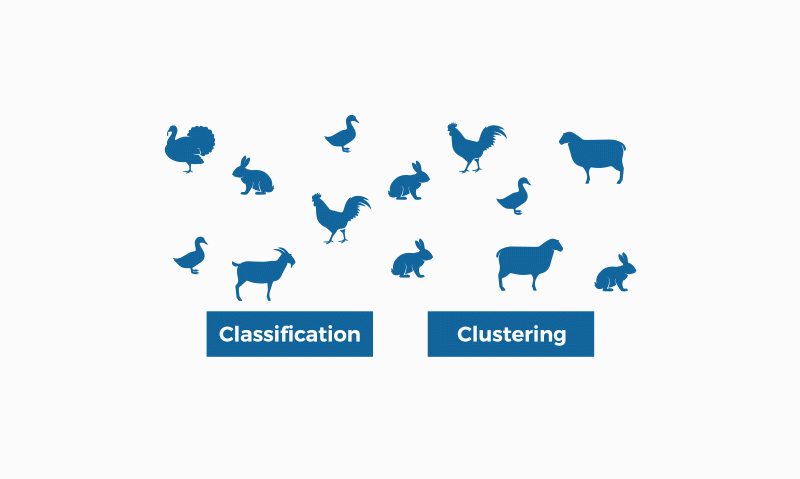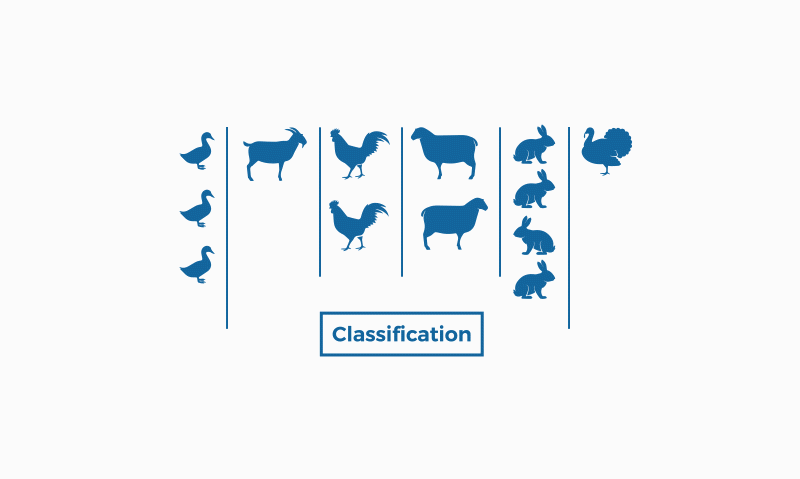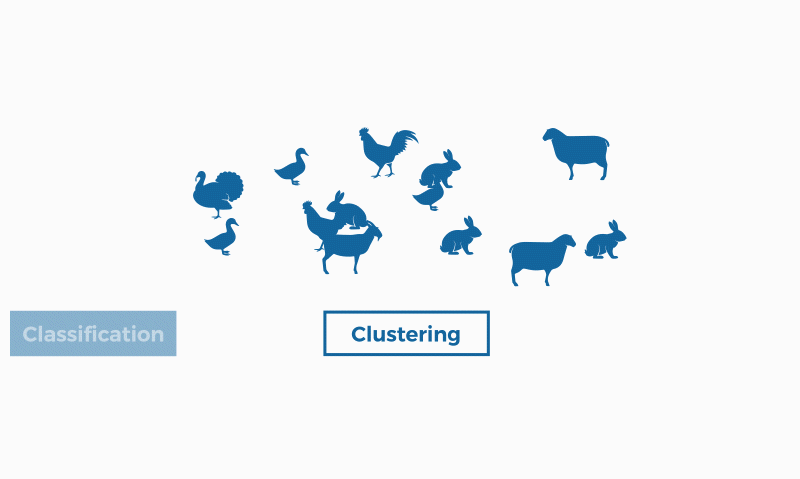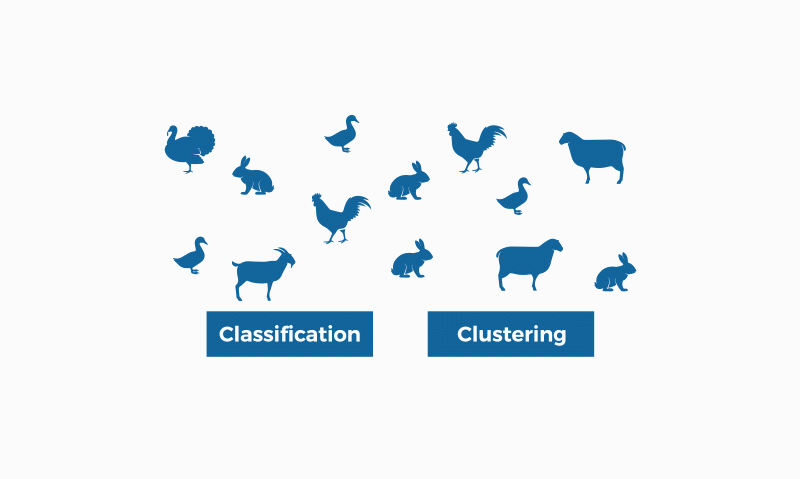
La clasificación y la clusterización son dos técnicas empleadas por el machine learning para encontrar patrones.
La clasificación y la clusterización son dos métodos de identificación de patrones usados en el machine learning (también conocido como "aprendizaje automático"). Aunque ambas técnicas tienen ciertas similitudes, la diferencia está en el hecho de que la clasificación se sirve de unas clases predefinidas en las que se asignan los objetos, mientras que la clusterización identifica similitudes entre objetos, que agrupa según esas características en común y que les diferencian de los otros grupos de objetos. Estos grupos se conocen como “clústeres” o “clusters”.
En el campo del machine learning (un tipo de inteligencia artificial), la clusterización se enmarca en el aprendizaje no supervisado; es decir, para este tipo de algoritmos solo disponemos de un conjunto de datos de entrada (no etiquetados), sobre los que debemos obtener información, sin conocer previamente cuál será la salida.
La clusterización se usa en proyectos para empresas que quieren encontrar aspectos en común dentro de sus clientes para encontrar grupos y enfocar productos o servicios, algo parecido a la segmentación de clientes o customer segmentation. Así, si un porcentaje significativo de los clientes tiene ciertos aspectos en común (edad, tipo de familia, etc.) se puede justificar una determinada campaña, servicio o producto.
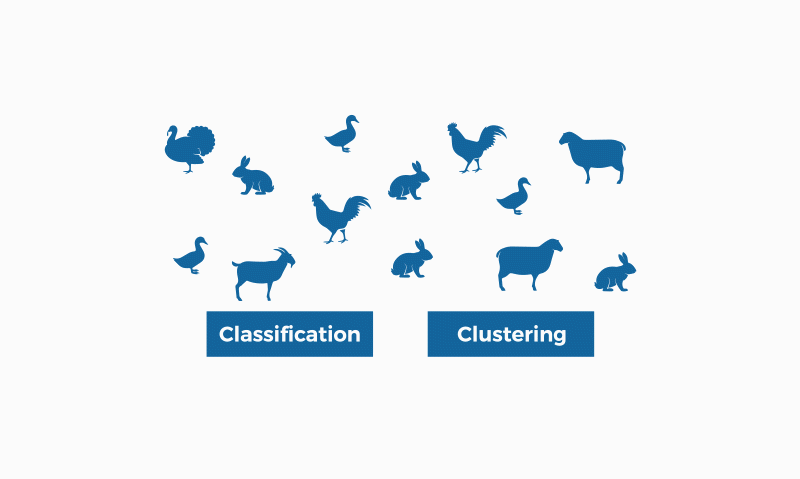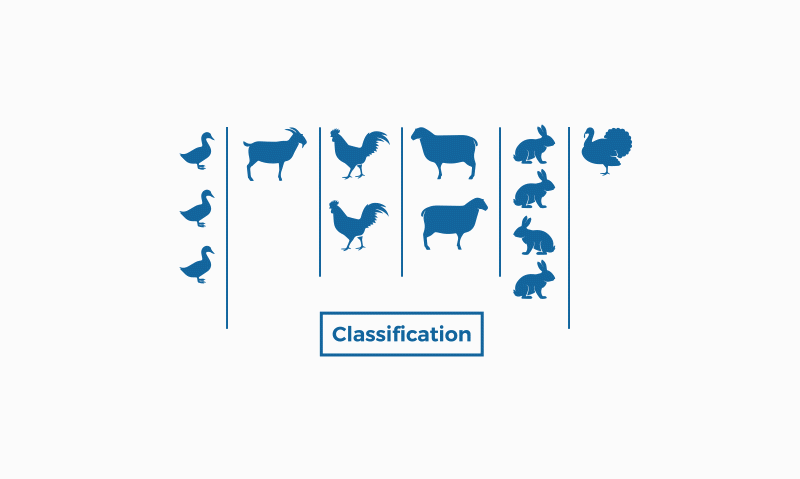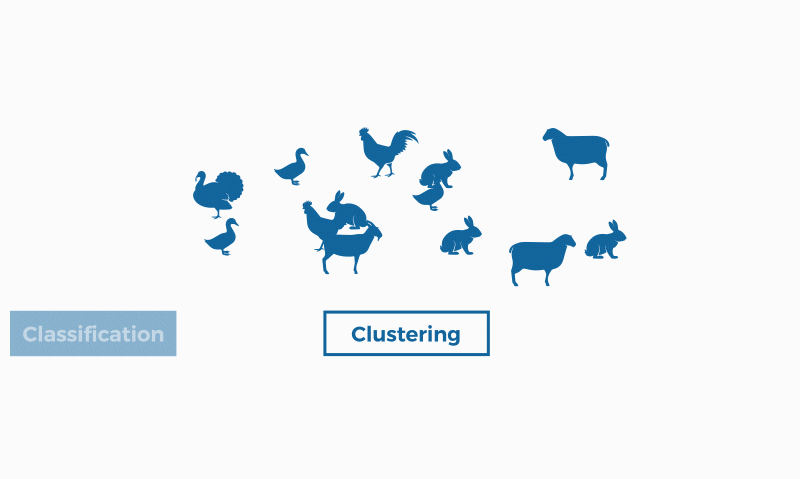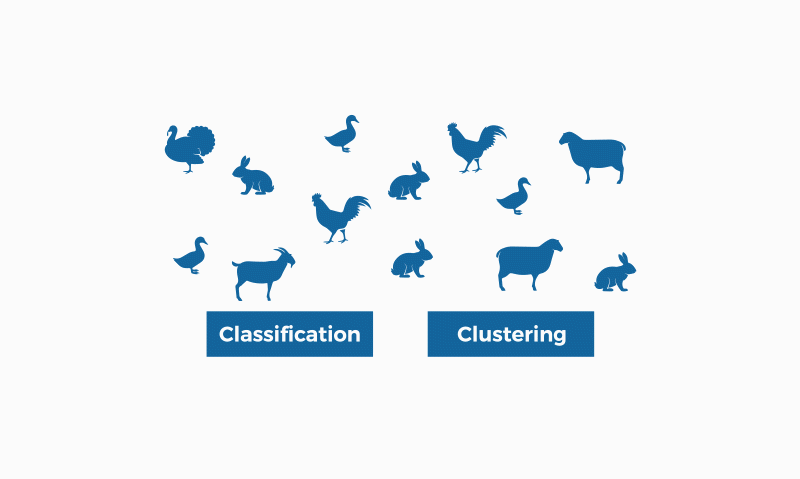
En cambio, la clasificación pertenece al aprendizaje supervisado. Esto significa que conocemos los datos de entrada (etiquetados en este caso) y conocemos las posibles salida del algoritmo. Existe la clasificación binaria que da respuesta a problemas con respuestas categóricas (como “sí” y “no”, por ejemplo), y la multiclasificación, para problemas donde nos encontramos con más de dos clases, respondiendo a respuestas más abiertas, como “estupendo”, “regular” e “insuficiente”.
La clasificación se usa en muchísimos campos, como la biología o en la clasificación decimal de Dewey para los libros, en la detección de spam en los correos electrónicos…
En ambos casos estas tecnologías dependen de grandes cantidades de datos (Big Data). ¿Te interesan el Big Data y el análisis de datos? ¡Descárgate nuestro Libro Blanco exclusivo y gratuito sobre Big Data!

En Bismart, empresa partner Power BI de Microsoft, utilizamos la clasificación y la clusterización en nuestros proyectos, que se enmarcan en muchos sectores diferentes. Por ejemplo, en el sector de los servicios sociales, hemos utilizado la clusterización para identificar grupos de población que usan servicios sociales concretos. A partir de los datos de los servicios sociales, hemos podido identificar o clusterizar los grupos de personas que usan servicios similares según sus atributos (número de personas a cargo, grado de dependencia, estado civil…). Así, hemos podido detectar qué tipo de servicio necesitará un nuevo usuario de servicios sociales de antemano comparando sus atributos con los de los clústers.
La clasificación se usa cuando se necesita conocer a los usuarios o clientes para decidir qué productos o campañas se lanzarán en el futuro. Por ejemplo, en Bismart desarrollamos un proyecto para el sector de los seguros en el que el cliente necesitaba clasificar los clientes en función de la siniestralidad, de forma que se pudo clasificar la póliza según el número de siniestros que se predecían. Así, la compañía puede escoger los clientes con un menor número de siniestros y descartar a los que presentan un número elevado.
Ejemplos prácticos
Netflix
Una aplicación muy conocida de los algoritmos de clusterización son los sistemas de recomendación de Netflix. Aunque la compañía es bastante discreta con sus algoritmos, está confirmado que existen unos 2.000 clústeres o comunidades que tienen gustos audiovisuales comunes. El Cluster 290 es el que incluye a las personas a las que les gustan las series “Lost”, “Black Mirror” y “Groundhog Day”. Netflix utiliza estos clústeres para afinar y precisar su conocimiento sobre los gustos de los espectadores y así poder tomar mejores decisiones en la creación de nuevas series originales.
Detección de fraude
La clasificación se usa de forma común para garantizar la seguridad de los datos en el sector financiero. En la era de las transacciones online donde el uso del dinero en efectivo ha disminuido notablemente, es necesario determinar si los movimientos realizados a través de tarjetas son seguros. Las entidades pueden clasificar las transacciones en correctas o fraudulentas usando datos históricos del comportamiento de los clientes para poder así detectar el fraude con mucha precisión.
Conclusión
Si este contenido ha sido de tu interés, te recomendamos descargar el libro blanco sobre Big Data donde encontrarás todo lo que necesitas saber sobre data analytics, inteligencia artificial y mucho más.


