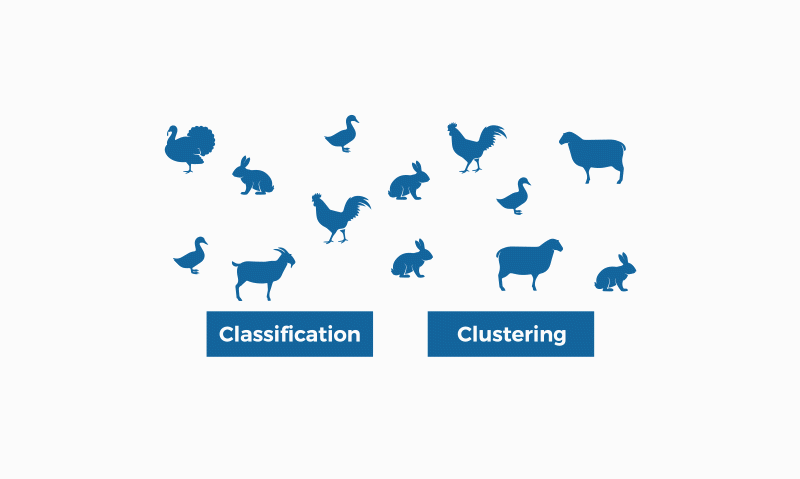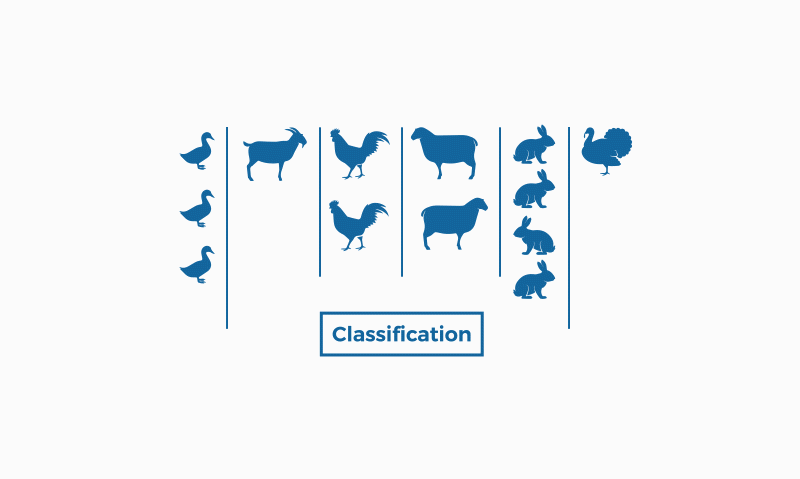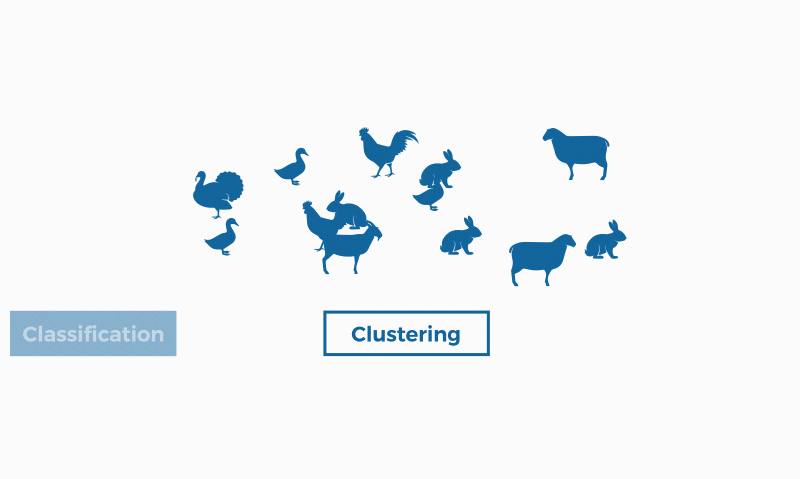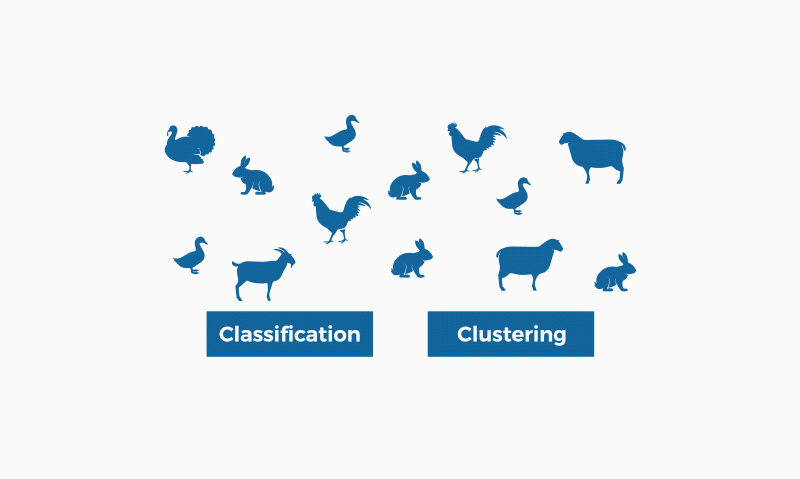
Classificació i clusterització són mètodes d'identificació de patrons usats en l'aprenentatge automàtic. T'expliquem quines són les seves diferències.
La classificació i la clusterització són dos mètodes d'identificació de patrons usats en l'aprenentatge automàtic (també conegut com "machine learning"). Encara que totes dues tècniques tenen certes similituds, la diferència rau en el fet que la classificació se serveix d'unes classes predefinides en les quals s'assignen els objectes, mentre que la clusterització identifica similituds entre objectes, que agrupa segons aquestes característiques en comú i que els diferencien dels altres grups d'objectes. Aquests grups es coneixen com a “clústers”.
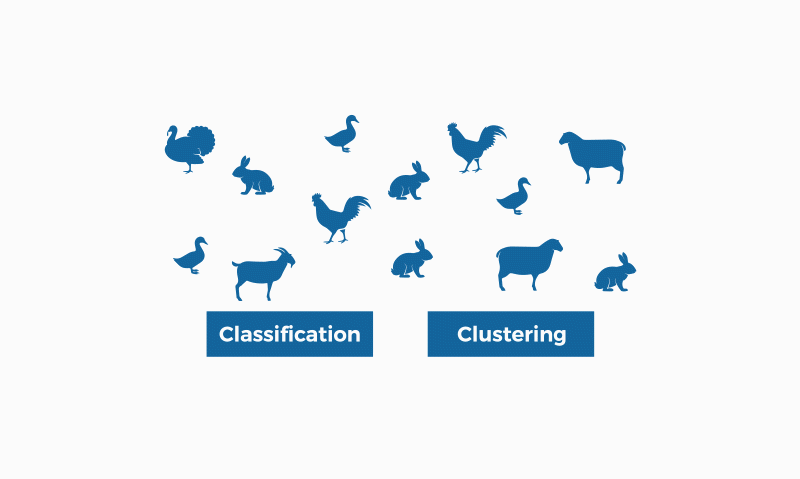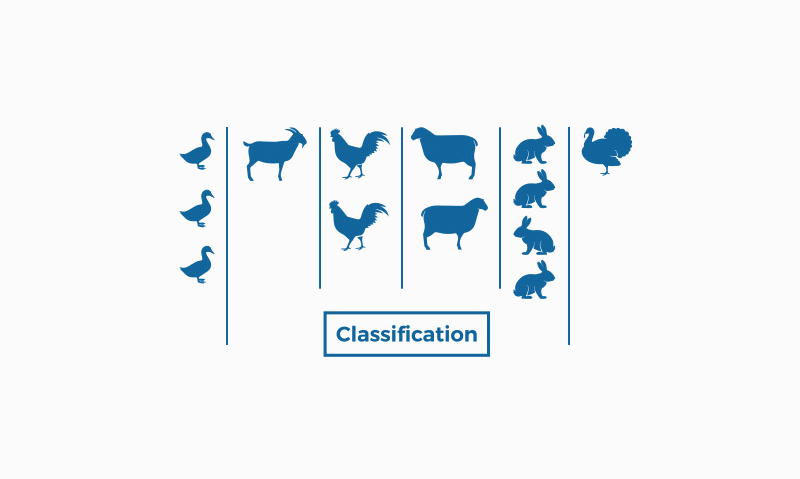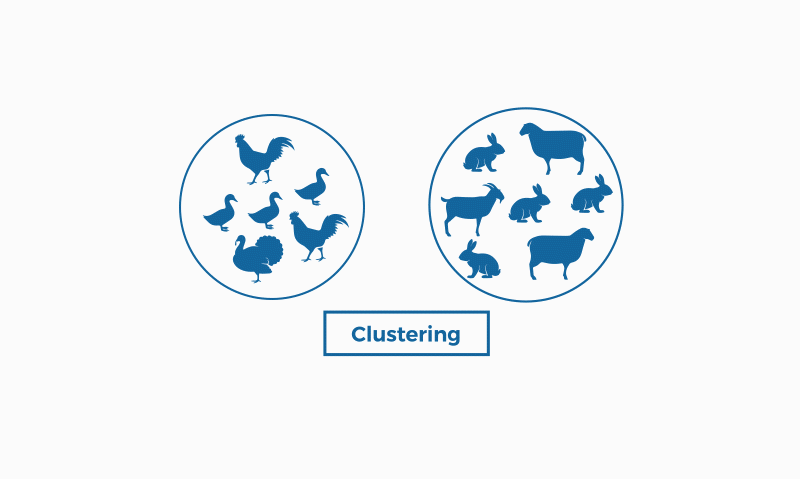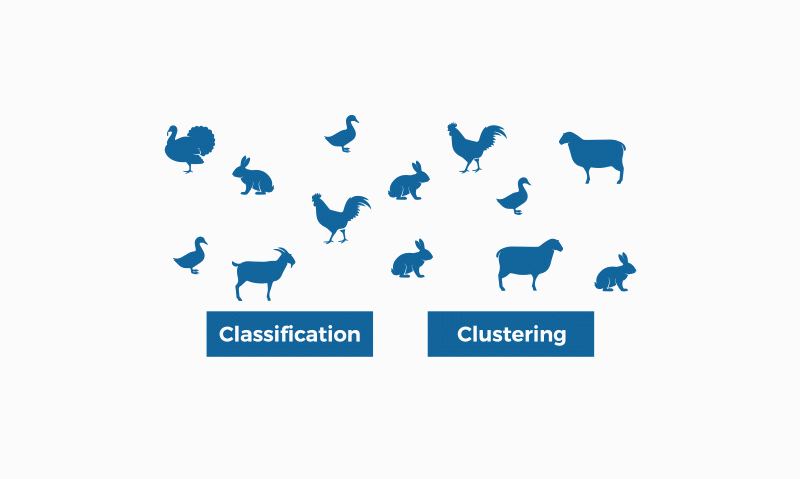
En el camp del machine learning (un tipus d'intel·ligència artificial), la clusterització s'emmarca en l'aprenentatge no supervisat; és a dir, per a aquest tipus d'algoritmes només disposem d'un conjunt de dades d'entrada (no etiquetades), sobre els quals hem d'obtenir informació, sense conèixer prèviament quina serà la sortida.
La clusterització s'usa en projectes per a empreses que volen trobar aspectes en comú dins dels seus clients per trobar grups i enfocar productes o serveis, algo similar a la segmentació de clients o customer segmentation. Així, si un percentatge significatiu dels clients tenen certs aspectes en comú (edat, tipus de família, etc.) es pot justificar una determinada campanya, servei o producte.
En canvi, la classificació pertany a l'aprenentatge supervisat, la qual cosa significa que coneixem les dades d'entrada (etiquetades en aquest cas) i coneixem les possibles sortides de l'algoritme. Hi ha la classificació binària que dona resposta a problemes amb respostes categòriques (com “sí” i “no”, per exemple), i la multiclasificació, per a problemes on ens trobem amb més de dues classes, responent a preguntes més obertes com ara “fantàstic”, “regular” i “insuficient”.
La classificació s'usa en moltíssims camps, com ara la biologia o en la classificació decimal de Dewey per als llibres, en la detecció d'espam als correus electrònics…
En tots dos casos aquestes tecnologies depenen de grans quantitats de dades (Big Data). T'interessen el Big Data i l'anàlisi de dades? Descarrega't el nostre Llibre blanc exclusiu i gratuït sobre Big Data!
A Bismart, empresa partner Power BI de Microsoft, utilitzem la classificació i la clusterización en els nostres projectes, que s'emmarquen en molts sectors diferents. Per exemple, en el sector dels serveis socials, hem utilitzat la clusterització per identificar grups de població que usen serveis socials concrets. A partir de les dades dels serveis socials, hem pogut identificar o clusteritzar els grups de persones que usen serveis similars segons els seus atributs (nombre de persones a càrrec, grau de dependència, estat civil…). Així, hem pogut detectar quin tipus de servei necessitarà un nou usuari de serveis socials per endavant comparant els seus atributs amb els dels clústers.
La classificació s'usa quan es necessita conèixer als usuaris o clients per decidir quins productes o campanyes es llançaran en el futur. Per exemple, a Bismart hem desenvolupat un projecte per al sector de les assegurances en el qual el client necessitava classificar els clients en funció de la sinistralitat, de manera que es va poder classificar la pòlissa segons el nombre de sinistres que es predeien. Així, la companyia pot triar els clients amb un menor nombre de sinistres i descartar els que presenten unes xifres més elevades.
Exemples
Netflix
Una aplicació molt coneguda dels algoritmes de clusteritzación són els sistemes de recomanació de Netflix. Encara que la companyia és bastant discreta amb els seus algoritmes, està confirmat que existeixen uns 2.000 clústers o comunitats que tenen gustos audiovisuals comuns. El Clúster 290 és el que inclou a les persones a les quals els agraden les sèries “Lost”, “Black Mirror”i “Groundhog Day”. Netflix utilitza aquests clústers per afinar i precisar el seu coneixement sobre els gustos dels espectadors i així poder prendre millors decisions en la creació de noves sèries originals.
Detecció de frau
La classificació s'usa de forma comuna per a garantir la seguretat de les dades en el sector financer. A l'era de les transaccions online on l'ús dels diners en efectiu ha disminuït notablement, és necessari determinar si els moviments realitzats a través de targetes són segurs. Les entitats poden classificar les transaccions en correctes o fraudulentes usant dades històriques del comportament dels clients per a poder així detectar el frau amb molta precisió.
Conclusió
Si aquest contingut ha estat del teu interès, et recomanem descarregar el llibre blanc sobre Big Data on trobaràs tot el que necessites saber sobre data analytics, intel·ligència artificial i molt més.


