Descobreix què és Azure Databricks, per a què serveix i els motius pels quals és la plataforma d'anàlisi de macrodades en el núvol líder del mercat.
De la creixent necessitat de processar majors quantitats de dades en el menor temps possible i del furor per l'emmagatzematge de dades al núvol, neix Azure Databricks, que, segons els experts, és de les plataformes d'anàlisi de dades cloud més completes del mercat. Però, què és Azure Databricks i per a què serveix?
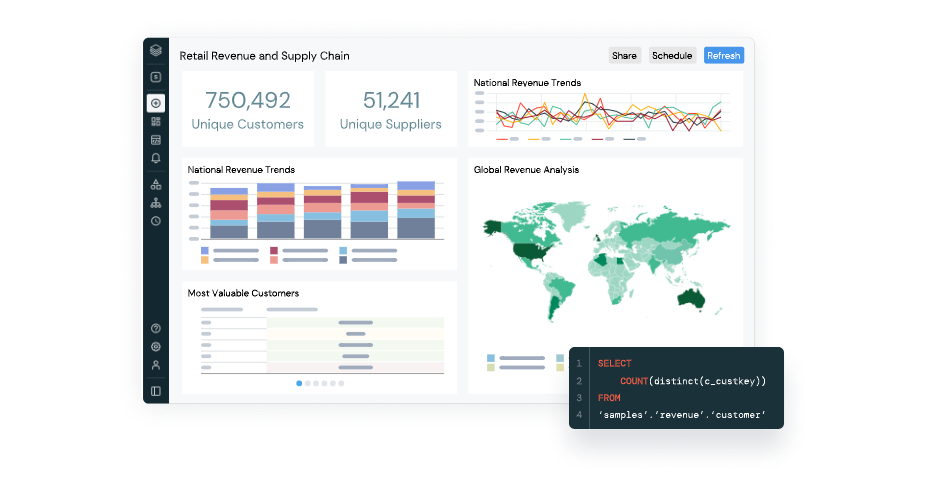
Font: Databricks
L'agost passat, Ali Ghodsi, cofundador i CEO de Databricks anunciava que la plataforma havia arribat als 38 bilions de dòlars després d'una nova inversió de 1.600 milions.
L'èxit de la plataforma és evident i, entre altres coses, està vinculat als requisits d'un món cada vegada més ràpid i digitalitzat:
- La necessitat de les organitzacions de processar una major quantitat de dades (Big Data) en menys temps.
- La migració progressiva de les dades i les plataformes d'anàlisi de dades cap a l'entorn cloud.
- La necessitat de les empreses de disposar d'espais de treball col·laboratius en el núvol que permetin la integració de dades i la integració de sistemes.
Aquestes són, segurament, les tres principals circumstàncies que han fet d'Azure Databricks una de les plataformes d'anàlisi de dades en el núvol líders del mercat.
Databricks ha sabut adaptar el seu funcionament als requeriments compartits de científics de dades, analistes de dades, enginyers de dades i analistes de negoci.
Què és Azure Databricks i per a què serveix?
Azure Databricks és una eina d'anàlisi de dades cloud pensada per a executar i transformar macrodades (estructurades i no estructurades). Es tracta d'una plataforma analítica unificada que ofereix als usuaris un espai de treball col·laboratiu i interactiu per a la transformació i exploració de les dades i que integra una gran quantitat de llenguatges de programació —R, Python, SQL i Scala—, així com entorns i llibreries com PyTorch, Keras, GraphX, Tensorflow i Scikit-learn.
La funció principal d'Azure Databricks és la transformació, preparació i anàlisi de les dades que posteriorment seran traslladades a altres plataformes per al seu consum. Es tracta d'un entorn clau per a l'analítica i la transformació de les dades en informació processable.
Així, Databricks és un servei intermedi entre les fonts d'origen de les dades i la seva destinació final, que habilita tasques de ciència de dades, d'anàlisis de dades, enginyeria de dades i intel·ligència artificial. A causa de la seva estructura multifuncional, Databricks té múltiples casos d'ús: machine learning, streaming, processament batch, deep learning, administració de fluxos de dades, ETL, etc.
Sens dubte, la principal virtut d'Azure Databricks és la seva òptima capacitat de processament —la plataforma està construïda sobre el motor de processament Spark—, que habilita la creació de clústers en qüestió de segons. Azure Databricks inclou l'última versió Databricks (10) al costat de l'última versió de Spark, amb el que aconsegueix una velocitat superior a la de la majoria d'eines del mercat. La seva velocitat és 8 vegades superior a la de Prest, 5 vegades superior a la de Vanilla Apatxe Spark en AWS i 3 vegades superior a la de Cloudera Impala.
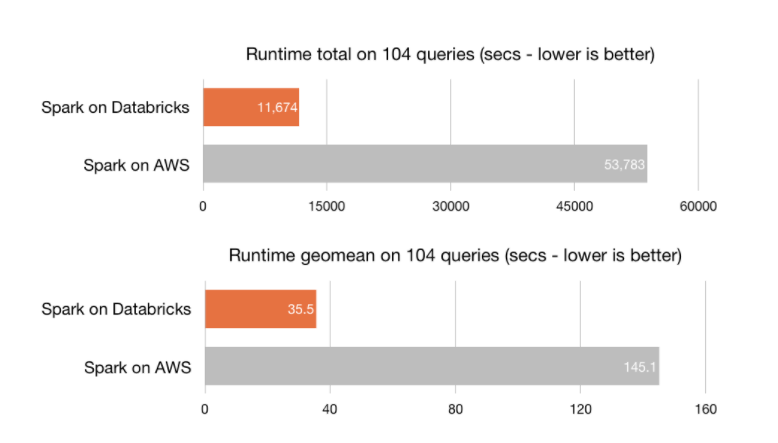
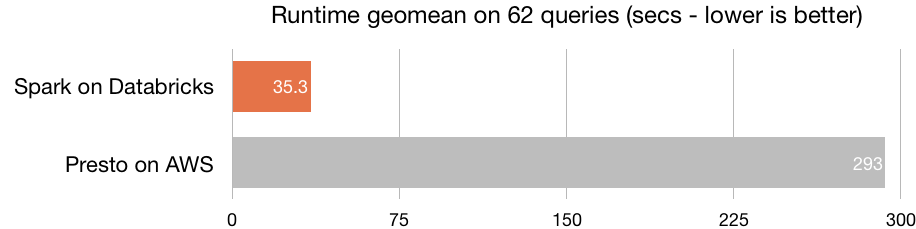
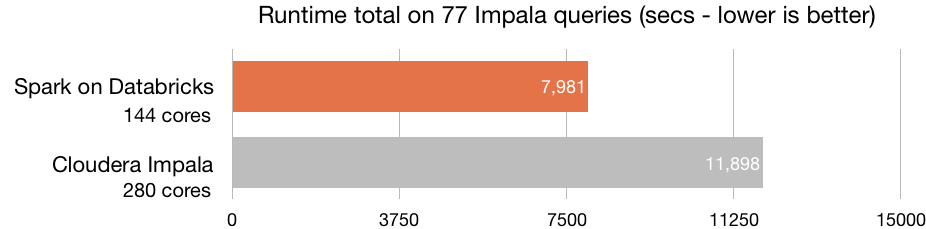
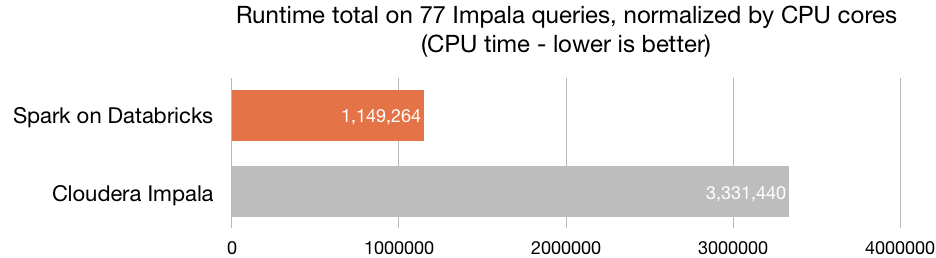
Font: Databricks
Una altra de les seves capacitats més valorades és que permet configurar el motor de processament que executa els codis en funció de les necessitats de l'usuari. És ideal per a redimensionar i escalar clústers segons requeriments.
A més, és una plataforma pensada per al núvol. S'executa a Azure, la plataforma cloud de Microsoft i, per tant, és un software com a servei (SaaS).
Azure Databricks: Com funciona?
Azure Databricks es desplega en tres entorns:
- Databricks SQL: Per a l'execució de consultes SQL i el desenvolupament de múltiples tipus de visualització per a l'exploració dels resultats de les queries des de diferents punts de vista. També habilita la creació de dashboards i permet compartir-los amb altres usuaris o entorns.
- Databricks Data Science & Engineering: És l'espai de treball principal de Databricks. Està pensat per a fomentar el treball col·laboratiu entre enginyers de dades, científics de dades, analistes de dades, business analysts i enginyers de machine learning. Inclou eines per al deployment en producció i l'administració de pipelines i simplifica la creació de prototips i l'exploració de dades.
- Databricks Machine Learning: És un entorn complet de machine learning: des del seguiment d'experiments i la creació i entrenament de models, fins al desenvolupament i l'administració de característiques. S'integra amb altres components de machine learning com Kafka, Hadoop, Tensorflow o XGBoost.
Databricks facilita les tasques mitjançant els seus espais de treball col·laboratius anomenats 'Notebooks'. En els 'Notebooks' es poden crear models, jobs i quadres de comandament per a l'administració de clústers. A més, permeten establir directoris independents per als diferents equips de treball que necessiten recursos dinàmics i desplegaments ad hoc. També es poden establir dependències entre Notebooks per al reaprofitament de codi.
Arquitectura i flux de dades Azure Databricks
Com hem vist, Azure Databricks és una eina dinàmica que permet una gran varietat de possibilitats. La seva diversitat la posiciona com l'eina on tot passa des del moment en el qual les dades són extretes de la font d'origen fins que finalment són emmagatzemades en un data warehouse.
En tractar-se d'una eina que s'executa en el núvol d'Azure, proporciona seguretat de dades a nivell d'empresa amb Azure Active Directory. La plataforma també combat la pèrdua de dades i informació amb còpies de seguretat automàtiques que es complementen amb alertes i un servei de monitoratge de processos. D'altra banda, suporta l'aplicació d'algunes polítiques de data governance, permetent habilitar permisos a nivell d'usuari per a l'accés als 'Notebooks', als clústers i als conjunts de dades.
A més, la plataforma és compatible amb totes les eines de Microsoft, sent una peça més d'un flux de dades que no té fi. Microsoft ha sabut desplegar un entorn complet de data analytics mitjançant múltiples eines, serveis i plataformes que s'integren entre elles i aconsegueixen que puguem fer pràcticament qualsevol cosa sense haver de sortir de l'entorn Microsoft.
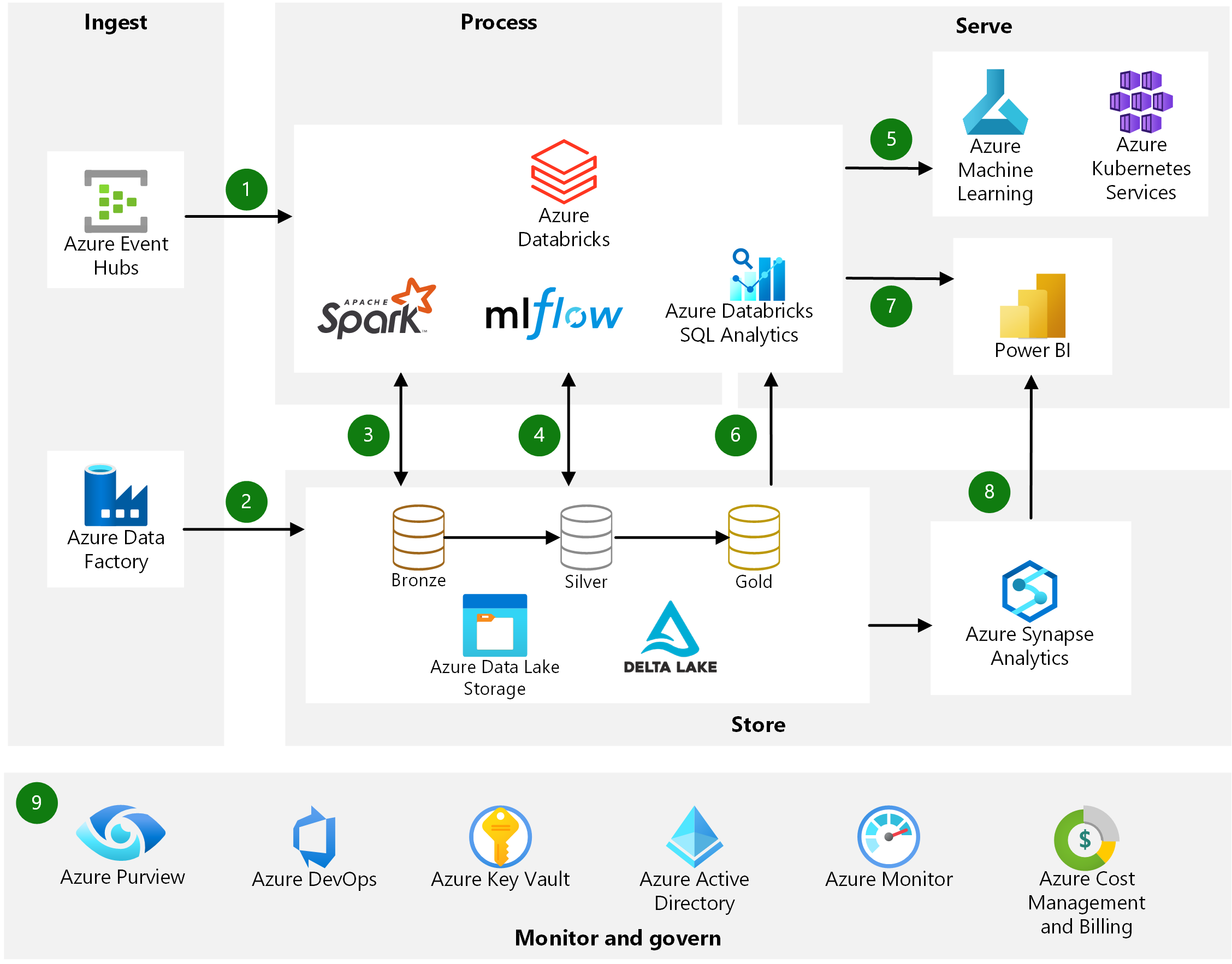
Font: Azure Databricks
Pel que fa a Azure Databricks, el flux de dades parteix de la font de dades. Les dades s'emmagatzemen en l'àrea de treball d'Azure Databricks. Científics de dades, enginyers i analistes de dades treballen de manera col·laborativa per a transformar i analitzar les dades que, una vegada preparades, poden ser emmagatzemades en un data warehouse o en un data lake, o bé ser exportades a plataformes d'anàlisis i business intelligence com Power BI. Les dades també poden ser aplicades en projectes de machine learning en el mateix entorn Databricks.
De Spark a Azure Databricks: la comercialització de l'open source
Azure Databricks uneix les capacitats de Spark, Databricks i Azure. De fet, Databricks va començar sent Spark, un motor de processament de dades a gran escala de codi obert creat en la Universitat UC Berkerley l'any 2010.
Amb els anys i després del seu èxit inicial, Spark s'ha anat actualitzant amb versions cada vegada més potents. No obstant això, l'ús de Spark a nivell empresarial presenta diversos problemes:
- Requereix d'un sistema d'emmagatzematge distribuït amb una gran quantitat de nodes per a poder ser executat.
- Necessita altres tecnologies com Hadoop o Mesos, per exemple.
- Els components per a l'administració de l'acompliment són limitats i el procés bastant complex.
- Spark no disposa d'eines per a la gestió de la capacitat i l'optimització de costos.
Per a solucionar aquestes dificultats i poder oferir un servei eficient a les empreses, els creadors originals de Spark van fundar l'empresa Databricks l'any 2013. Així, Databricks es va convertir en la versió comercial de Spark que resolia les limitacions de la versió open source.
Anys més tard, amb la unió de Databricks i Azure, Azure Databricks es consolida com una de les plataformes de processament de macrodades en el núvol més potents del mercat, combinant la velocitat del motor Spark amb els avantatges de l'entorn cloud de Microsoft.
Volum, varietat i velocitat en una sola plataforma
Des que el Big Data es va convertir en una realitat, l'èmfasi s'ha posat en les ja famoses 3V del Big Data: volum, varietat i velocitat; els requisits que ha de complir qualsevol solució tecnològica de Big Data.
Fins a l'aparició d'Azure Databricks, les 3V es desenvolupaven en eines independents, cosa que suposava que les tasques d'analítica Big Data, analítica predictiva i machine learning eren dutes a terme per equips diferenciats.
No obstant això, Azure Databricks ha aconseguit construir un entorn que uneix totes aquestes tasques i equips en un mateix espai. Azure Databricks suporta el volum, la velocitat i la varietat necessaris per a dur a terme en qualsevol mena de projecte de macrodades.
Aquest article ha estat escrit amb la col·laboració de Joan Teixidó, Data Engineer a Bismart i Luís Martín, Data Scientist a Bismart.


