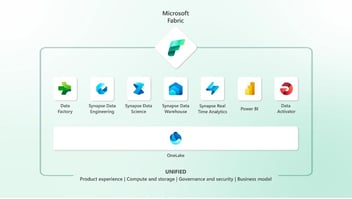
Descubre qué es Azure Databricks, para qué sirve y los motivos por los cuales es la plataforma de análisis de macrodatos en la nube líder del mercado.
De la creciente necesidad de procesar mayores cantidades de datos en el menor tiempo posible y del furor por el almacenaje de datos en la nube, nace Azure Databricks que, según los expertos, es de las plataformas de análisis de datos en la nube más completas del mercado. Pero, ¿qué es Azure Databricks y para qué sirve?
Fuente: Databricks
El pasado agosto de 2021, Ali Ghodsi, cofundador y CEO de Databricks anunciaba que la plataforma había llegado a los 38 billones de dólares tras una nueva inversión de 1.600 millones.
El éxito de la plataforma es evidente y, entre otras cosas, está vinculado a los requisitos de un mundo cada vez más rápido y digitalizado:
- La necesidad de las organizaciones de procesar una mayor cantidad de datos (Big Data) en menos tiempo.
- La migración progresiva de los datos y las plataformas de análisis de datos hacia el entorno cloud.
- La necesidad de las empresas de disponer de espacios de trabajo colaborativos en la nube que permitan la integración de datos y la integración de sistemas.
Estas son, seguramente, las tres principales circunstancias que han hecho de Azure Databricks una de las plataformas de análisis de datos en la nube líderes del mercado.
Databricks ha sabido adaptar su funcionamiento a los requerimientos compartidos de científicos de datos, analistas de datos, ingenieros de datos y analistas de negocio.
¿Qué es Azure Databricks y para qué sirve?
Azure Databricks es una herramienta de análisis de datos en la nube pensada para ejecutar y transformar macrodatos (estructurados y no estructurados). Se trata de una plataforma analítica unificada que ofrece a los usuarios un espacio de trabajo colaborativo e interactivo para la transformación y exploración de los datos y que integra una gran cantidad de lenguajes de programación —R, Python, SQL y Scala—, así como entornos y librerías como PyTorch, Keras, GraphX, Tensorflow y Scikit-learn.
La función principal de Azure Databricks es la transformación, preparación y análisis de los datos que posteriormente serán trasladados a otras plataformas para su consumo. Se trata de un entorno clave para la analítica y la transformación de los datos en información procesable.
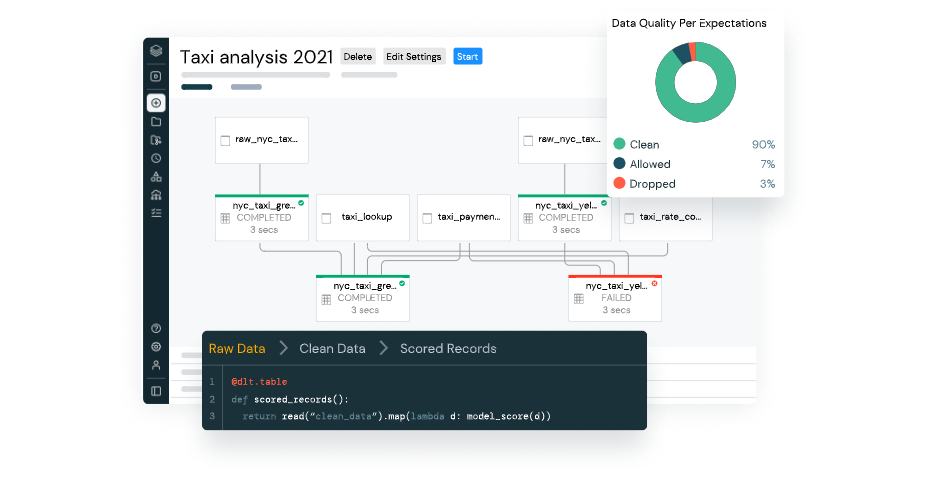
Así, Databricks es un servicio intermedio entre las fuentes de origen de los datos y su destino final que habilita tanto tareas de ciencia de datos, como de análisis de datos, ingeniería de datos e inteligencia artificial. Debido a su estructura multifuncional, Databricks tiene múltiples casos de uso: machine learning, streaming, procesamiento batch, deep learning, administración de flujos de datos, ETL, etc.
Sin duda, la principal virtud de Azure Databricks es su óptima capacidad de procesamiento —la plataforma está construida sobre el motor de procesamiento Spark—, que habilita la creación de clústers en cuestión de segundos. Azure Databricks incluye la última versión Databricks (10) junto a la última versión de Spark, con lo que consigue una velocidad superior a la de la mayoría de herramientas del mercado. Su velocidad es 8 veces superior a la de Presto, 5 veces superior a la de Vanilla Apache Spark en AWS y 3 veces superior a la de Cloudera Impala.
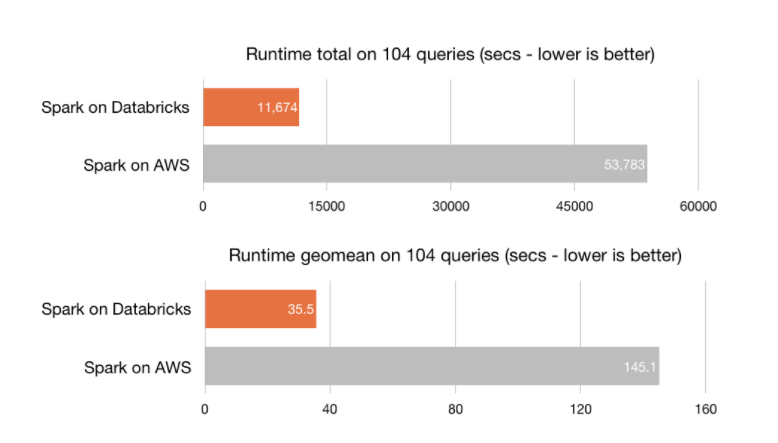
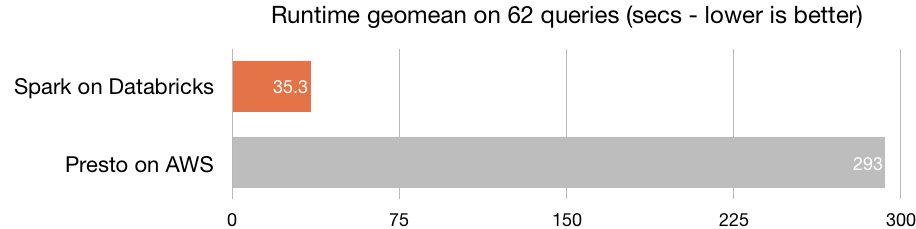
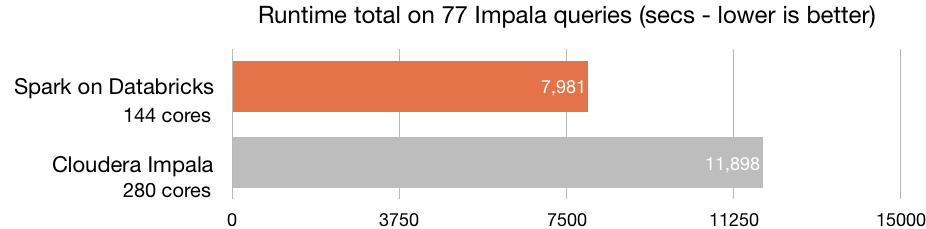
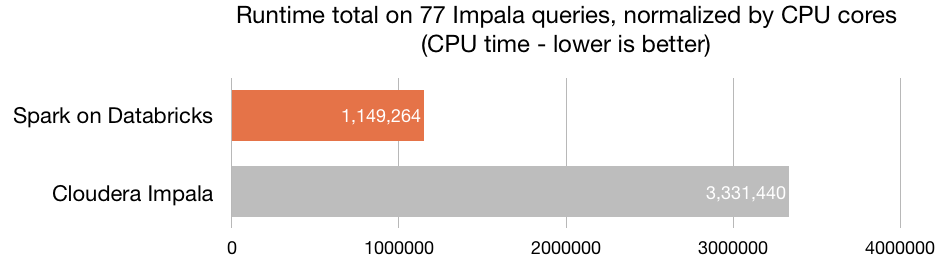
Fuente: Databricks
Otra de sus capacidades más valoradas es que permite configurar el motor de procesamiento que ejecuta los códigos en función de las necesidades del usuario. Es ideal para redimensionar y escalar clústers según requerimientos.
Además, es una plataforma pensada para la nube. Se ejecuta en Azure, la plataforma cloud de Microsoft y, por tanto, es un software como servicio (SaaS).
Azure Databricks: ¿Cómo funciona?
Azure Databricks se despliega en tres entornos:
- Databricks SQL: Para la ejecución de consultas SQL y el desarrollo de múltiples tipos de visualización para la exploración de los resultados de las queries desde diferentes puntos de vista. También habilita la creación de dashboards y permite compartirlos con otros usuarios o entornos.
- Databricks Data Science & Engineering: Constituye el espacio de trabajo principal de Databricks. Está pensado para fomentar el trabajo colaborativo entre ingenieros de datos, científicos de datos, analistas de datos, business analysts e ingenieros de machine learning. Incluye herramientas para el deployment en producción y la administración de pipelines y simplifica la creación de prototipos y la exploración de datos.
- Databricks Machine Learning: Es un entorno completo de machine learning: desde el seguimiento de experimentos y la creación y entrenamiento de modelos, hasta el desarrollo y la administración de características. Se integra con otros componentes de machine learning como Kafka, Hadoop, Tensorflow o XGBoost.
Databricks facilita las tareas mediante sus espacios de trabajo colaborativos llamados 'Notebooks'. En los 'Notebooks' se pueden crear modelos, jobs y cuadros de mando para la administración de clústers. Además, permiten establecer directorios independientes para los distintos equipos de trabajo que requieren de recursos dinámicos y despliegues ad-hoc. También se pueden establecer dependencias entre Notebooks para el reaprovechamiento de código.
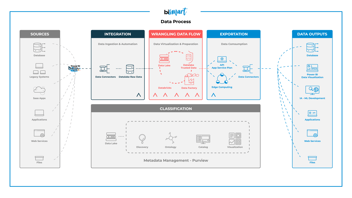
Arquitectura y flujo de datos Azure Databricks
Como hemos visto, Azure Databricks es una herramienta dinámica que permite una gran variedad de posibilidades. Su diversidad la posiciona como la herramienta donde todo pasa desde el momento en el que los datos son extraídos de la fuente de origen hasta que finalmente son almacenados en un data warehouse.
Al tratarse de una herramienta que se ejecuta en la nube de Azure, proporciona seguridad de datos a nivel de empresa con Azure Active Directory. La plataforma también elude la pérdida de datos e información con backups automáticos que se complementan con alertas y un servicio de monitorización de procesos. Por otro lado, soporta la aplicación de ciertas políticas de data governance, permitiendo habilitar permisos a nivel de usuario para el acceso a los 'Notebooks', a los clústers y a los conjuntos de datos.
Además, la plataforma es compatible con todas las herramientas de Microsoft, siendo una pieza de un flujo de datos que no tiene fin. Microsoft ha sabido desplegar un entorno completo de data analytics mediante múltiples herramientas, servicios y plataformas que se integran entre ellas y logran que podamos hacer prácticamente cualquier cosa sin tener que salir del entorno Microsoft.
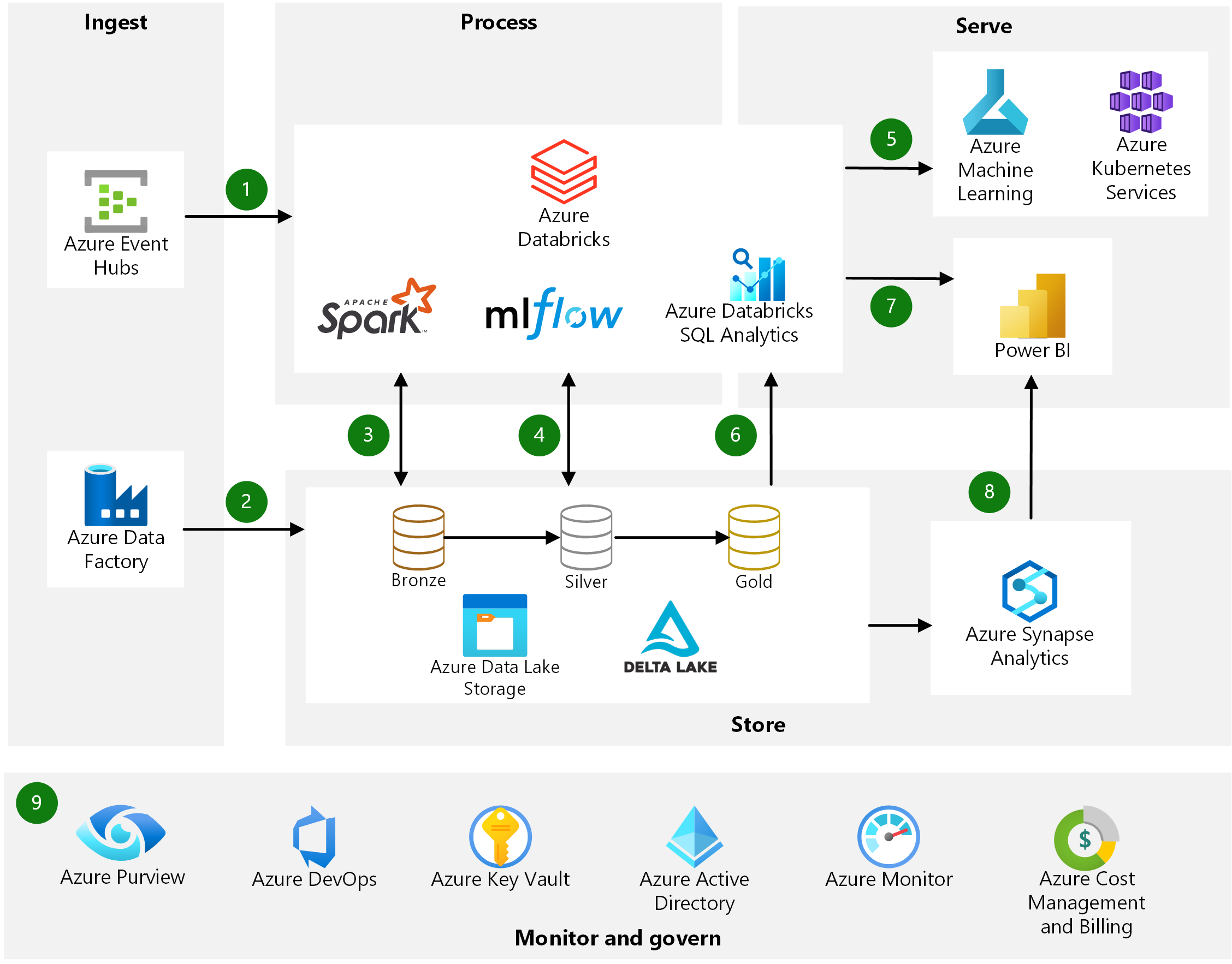
Fuente: Azure Databricks
En cuanto a Azure Databricks, el flujo de datos parte de la fuente de datos, que se almacenan en el área de trabajo de Azure Databricks. Científicos de datos, ingenieros y analistas de datos trabajan de forma colaborativa para transformar y analizar los datos que, una vez preparados, pueden ser almacenados en un data warehouse o en un data lake, o bien ser exportados a plataformas de análisis y business intelligence como Power BI. Los datos también pueden ser aplicados en proyectos de machine learning en el mismo entorno Databricks.
De Spark a Azure Databricks: la comercialización del open source
Azure Databricks une las capacidades de Spark, Databricks y Azure. De hecho, Databricks empezó siendo Spark, un motor de procesamiento de datos a gran escala de código abierto creado en la Universidad UC Berkerley en 2010.
Con los años y tras su éxito inicial, Spark se ha ido actualizando con versiones cada vez más mejoradas. No obstante, el uso de Spark a nivel empresarial presentaba varios problemas:
- Requería de un sistema de almacenamiento distribuido con una gran cantidad de nodos para poder ser ejecutado.
- Se necesitaba disponer de otras tecnologías como Hadoop o Mesos, por ejemplo.
- Los componentes para la administración del desempeño eran limitados y el proceso bastante complejo.
- Spark no dispone de herramientas para la gestión de la capacidad y la optimización de costos.
Para solucionar estas dificultades y poder ofrecer un servicio eficiente a las empresas, los creadores originales de Spark fundaron la empresa Databricks en 2013. Así, Databricks se convirtió en la versión comercial de Spark que resolvía las limitaciones de la versión open source.
Años más tarde, con la unión de Databricks y Azure, Azure Databricks se consolida como una de las plataformas de procesamiento de macrodatos en la nube más potentes del mercado, combinando la velocidad del motor Spark con las ventajas del entorno cloud de Microsoft.
Volumen, variedad y velocidad en una sola plataforma
Desde que el Big Data se convirtió en una realidad, el énfasis se ha puesto en las ya famosas 3V del Big Data: volumen, variedad y velocidad; los requisitos que debe cumplir cualquier solución tecnológica de Big Data.
Hasta la aparición de Azure Databricks, las 3V se desarrollaban en herramientas independientes, cosa que suponía que las tareas de analítica Big Data, analítica predictiva y machine learning fueran realizadas por equipos distintos.
Sin embargo, Azure Databricks ha conseguido componer un entorno que une todas estas tareas y equipos en un mismo espacio. Azure Databricks soporta el volumen, la velocidad y la variedad necesarios para llevar a cabo en cualquier tipo de proyecto de macrodatos.
Este artículo ha sido escrito con la colaboración de Joan Teixidó, Data Engineer en Bismart y Luís Martín, Data Scientist en Bismart.