Find out what Azure Databricks is, what companies use it for, and the reasons that make it the leading Big Data analytics platform in the cloud.
No one can deny the growing need to process larger amounts of data in the shortest time possible and the boom of data storage in the cloud. According to experts, Azure Databricks is one of the most complete cloud data analytics platforms on the market. But what is Azure Databricks and what is it for?
Source: Databricks
Last August 2021, Ali Ghodsi, co-founder and CEO of Databricks announced that the platform had reached $38 billion after a new investment of $1.6 billion.
The platform's success is apparent and, among other things, relates to the requirements of an increasingly fast-paced and digitized world:
- Companies' need to process a greater amount of data (Big Data) in less time.
- The migration of data and data analysis platforms to the cloud.
- Companies' need for collaborative workspaces in the cloud that enable data integration and system integration.
These are the three main circumstances that have made Azure Databricks one of the leading cloud data analytics platforms in the market.
Databricks has succeded in adaptong its functionality to the requirements of data scientists, data analysts, data engineers and business analysts.
What is Azure Databricks?
Azure Databricks is a cloud-based data analytics tool designed to run and transform Big Data (both structured and unstructured). It is a unified analytics platform that provides users with a collaborative and interactive workspace for data transformation and exploration and integrates many programming languages —R, Python, SQL and Scala— as well as libraries such as PyTorch, Keras, GraphX, Tensorflow and Scikit-learn.
Azure Databricks' main function is the transformation, preparation and analysis of data that will later be migrated to other platforms for their consumption. In short, it is a key environment for transforming data into actionable information.
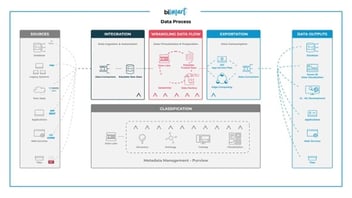
Databricks is an in-between service between the data source and data's final destination, as it enables data science, data analytics, data engineering and artificial intelligence. Due to its multifunctional structure, Databricks has multiple use cases: machine learning, streaming, batch processing, deep learning, data flow management, ETL, etc.
Without a doubt, Azure Databricks' main advantage is its optimal processing capacity —the platform is built on Spark—, which enables the creation of clusters in a matter of seconds. Azure Databricks includes the latest Databricks version (10) together with the latest version of Spark, achieving an optimal speed. It is 8 times faster than Presto, 5 times faster than Vanilla Apache Spark on AWS and 3 times faster than Cloudera Impala.
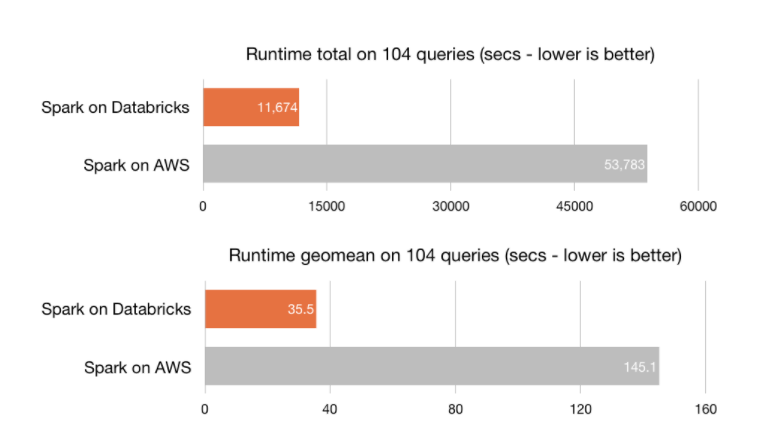
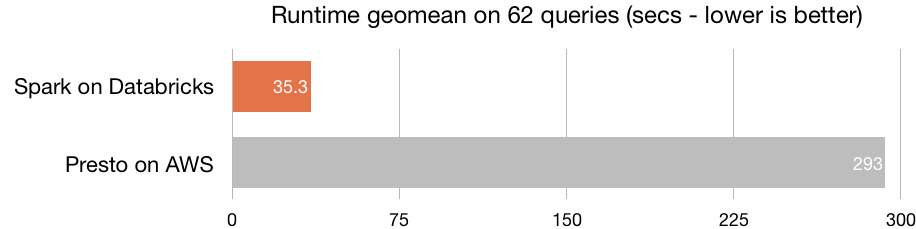
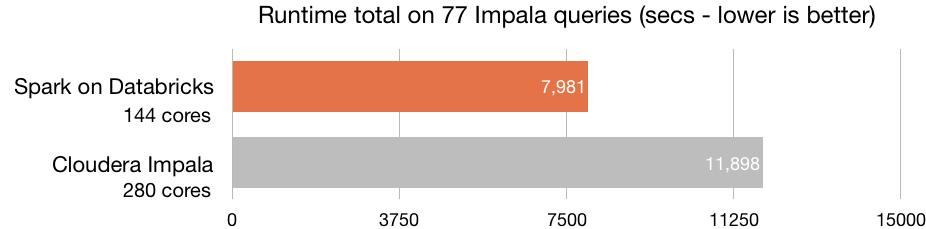
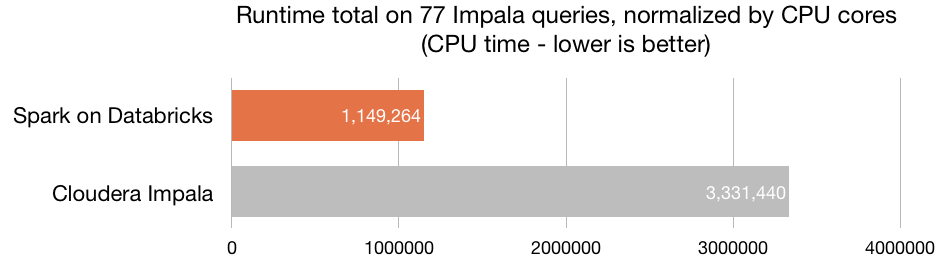
Source: Databricks
Otra de sus capacidades más valoradas es que permite configurar el motor de procesamiento que ejecuta los códigos en función de las necesidades del usuario. Es ideal para redimensionar y escalar clústers según requerimientos.
Another of its most valued capabilities is that it allows to set up the processing engine that executes the codes according to users' needs. It is ideal for resizing and scaling clusters according to requirements.
In addition, the platform has been designed for the cloud. It runs on Azure, Microsoft's cloud platform, so it is a software as a service (SaaS).
Azure Databricks: How does it work?
Azure Databricks has three different environments:
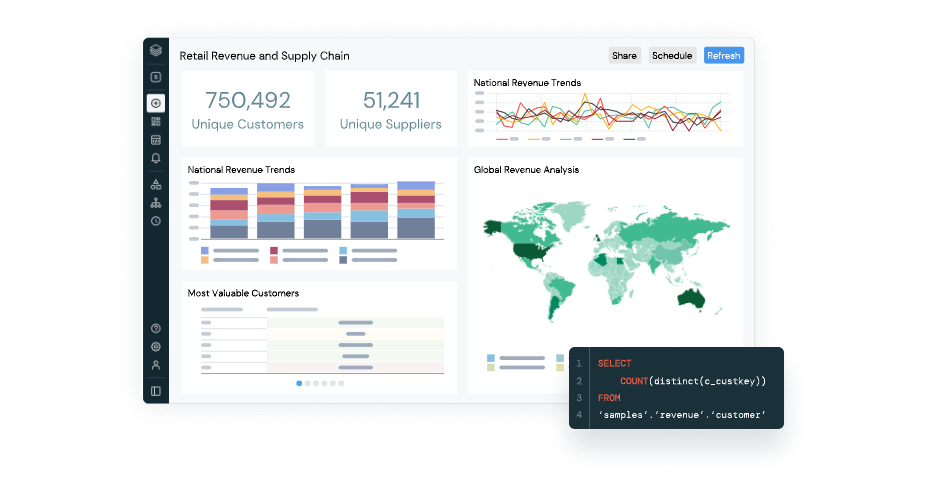
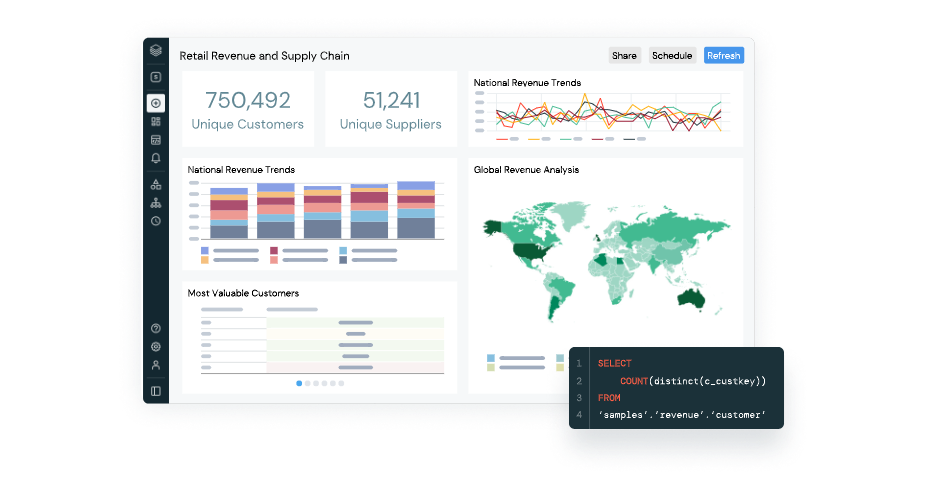
- Databricks SQL: For the execution of SQL queries and the exploration of query results from different points of view. It also enables the creation of dashboards and allows users to share them with other users or environments.
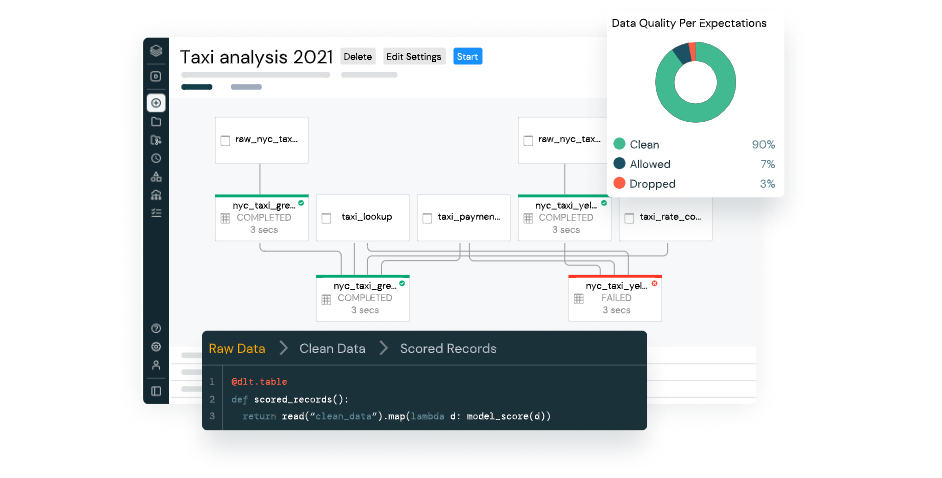
- Databricks Data Science & Engineering: It is Databricks' main workspace. It is designed to foster collaborative work between data engineers, data scientists, data analysts, business analysts and machine learning engineers. It includes tools for production deployment and pipeline management and simplifies prototyping and data exploration.
- Databricks Machine Learning: It is a complete machine learning environment: from experiment tracking and model creation and training, to feature development and management. It integrates with other machine learning components such as Kafka, Hadoop, Tensorflow or XGBoost.
Databricks simplifies tasks through its collaborative workspaces called 'Notebooks'. Notebooks can be used to create models, jobs and dashboards for cluster management. In addition, independent directories can be established for different work teams that require dynamic resources and ad-hoc deployments. Dependencies can also be established between Notebooks for reusing code.
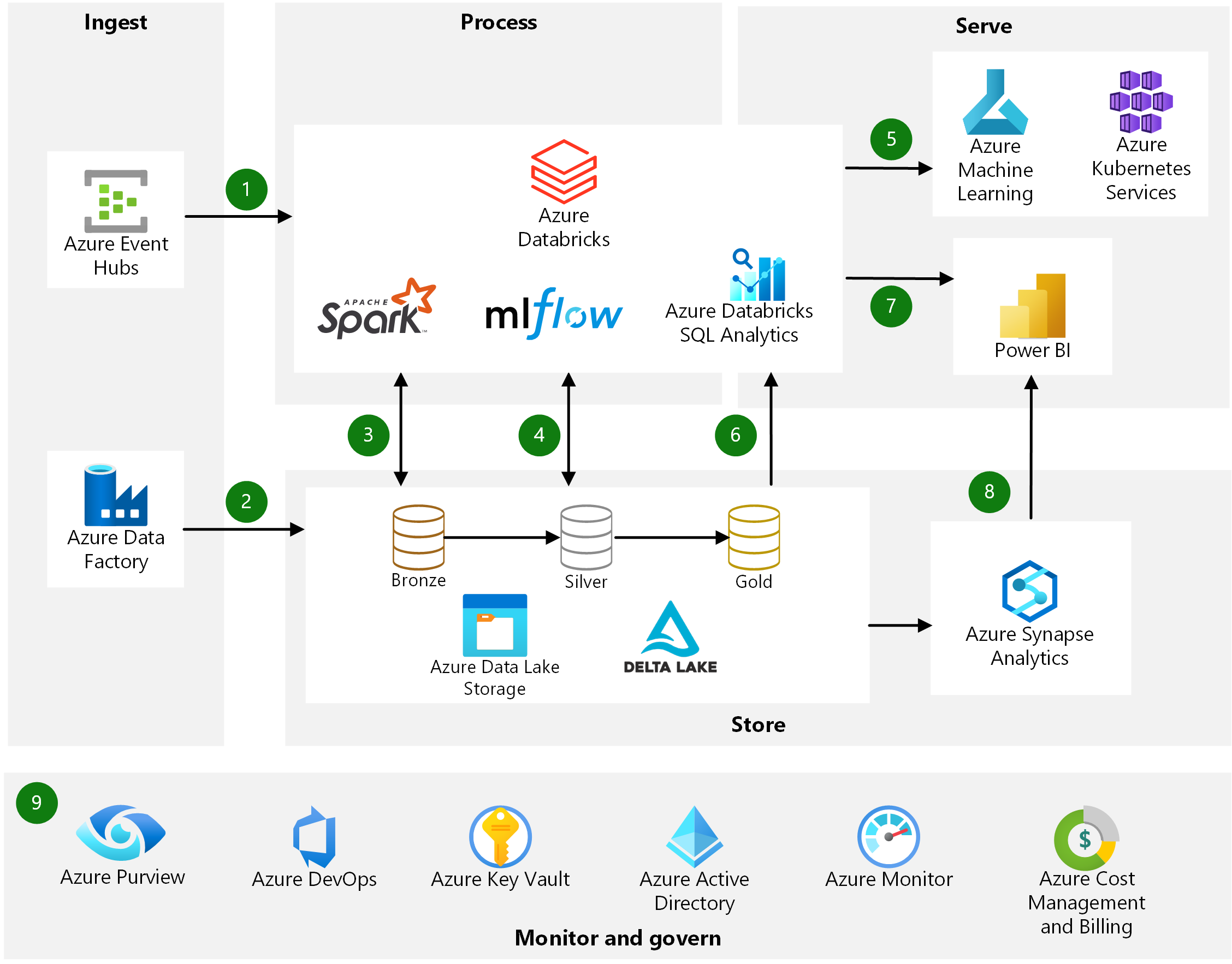
Azure Databricks architecture and data flow
As we have seen, Azure Databricks is a dynamic tool that allows a wide variety of possibilities. Its diversity positions it as the tool where everything happens from the moment the data is extracted from the source until it is finally stored in a data warehouse.
As a tool running in the Azure cloud, it provides enterprise-level data security with Azure Active Directory. The platform also prevents data and information loss with automatic backups that are complemented by alerts and a process monitoring service. On the other hand, it supports the application of data governance policies, enabling user-level permissions for access to notebooks, clusters and data sets.
In addition, the platform is compatible with all Microsoft tools, being a central piece of a never-ending data flow. Microsoft has succeeded in creating a complete data analytics environment through multiple tools, services and platforms that integrate with each other and allow users to do almost anything without leaving the environment.
 Source: Azure Databricks
Source: Azure Databricks
As for Azure Databricks, the data flow starts from the data source, which is stored in the Azure Databricks workspace. Data scientists, engineers and data analysts work collaboratively to transform and analyze the data, which, once prepared, can be stored in a data warehouse or data lake, or exported to analytics and business intelligence platforms such as Power BI. The data can also be used for machine learning projects in the Databricks environment.
From Spark to Azure Databricks: the commercialization of the open source
Azure Databricks brings together the capabilities of Spark, Databricks and Azure. In fact, Databricks started out as Spark, an open source large-scale data processing engine created at UC Berkerley University in 2010.
Over the years and following its initial success, Spark has been updated with incrementally improved versions. However, Spark was not created to be used by businesses and its enterprise level has several problems:
- It requires a distributed storage system with a large number of nodes to be executed.
- It needs other technologies such as Hadoop or Mesos, for example.
- The components for performance management are limited and the process quite complex.
- It does not have tools for capacity management and cost optimization.
To solve these problems and to be able to offer an efficient service to companies, the original creators of Spark founded the company Databricks in 2013. Thus, Databricks became the commercial version of Spark that solved the limitations of the open source version.
Years later, with the integration of Databricks and Azure, Azure Databricks is consolidated as one of the most powerful big data processing platforms in the market, combining the speed of the Spark engine with the advantages of Microsoft's cloud environment.
Volume, variety and velocity on a single platform
Since Big Data became a reality, the emphasis has been put on the now famous 3Vs of Big Data: volume, variety and velocity; the requirements that any Big Data technology solution must meet.
Until the appearance of Azure Databricks, the 3Vs were developed in separate tools, which meant that Big Data analytics, predictive analytics and machine learning tasks were performed by separate teams.
However, Azure Databricks has managed to create an environment that unites all these tasks and teams in the same space. Azure Databricks supports the volume, variey and velocity needed to carry out any type of Big Data project.
This article has been written with the collaboration of Joan Teixidó, Data Engineer at Bismart and Luís Martín, Data Scientist at Bismart.