¿Cómo transformamos los datos en valor empresarial? Descubre qué hacemos con los datos y los pasos y procesos de nuestro flujo de procesamiento de datos.
Prácticamente ya nadie duda del valor de los datos, que se han convertido en un activo imprescindible para las empresas. Sin embargo, el valor de los datos no es fortuito ni contingente. Los datos en su formato original son como un diamante en bruto. Desenmascarar el valor implica procesarlos, tratarlos, transformarlos... En definitiva, un largo proceso que incluye múltiples tareas, tecnologías y disciplinas.
Para convertir una piedra en un diamante es necesario que expertos en la materia sometan la piedra a un proceso de pulido y tallado. Para convertir datos en valor empresarial, pasa exactamente lo mismo.
El valor de los datos en su formato y hábitat original es mínimo y ciertamente insuficiente para que una empresa pueda aprovecharlos para la toma de mejores decisiones basadas en ellos (data-driven decisions).
Se suele decir que los datos son la base de la toma de decisiones empresariales. No obstante, esta afirmación no es del todo cierta. No son los datos en sí mismos los que ayudan a las compañías a mejorar su actividad, sino el conocimiento que contienen y que se esconde tras capas y capas de deshechos que necesitan ser eliminados. Los datos, igual que los diamantes, deben pasar por un proceso de pulido y tallado para ser de utilidad.
En Bismart llevamos años transformando datos en bruto en valor empresarial. Muchas personas no son conscientes o desconocen el proceso y el recorrido por el que deben pasar los datos para ser transformados en valor.
¿Qué hacemos con los datos? Procesamiento de datos
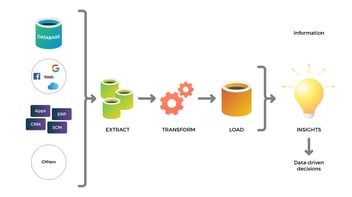
1. Extracción de datos
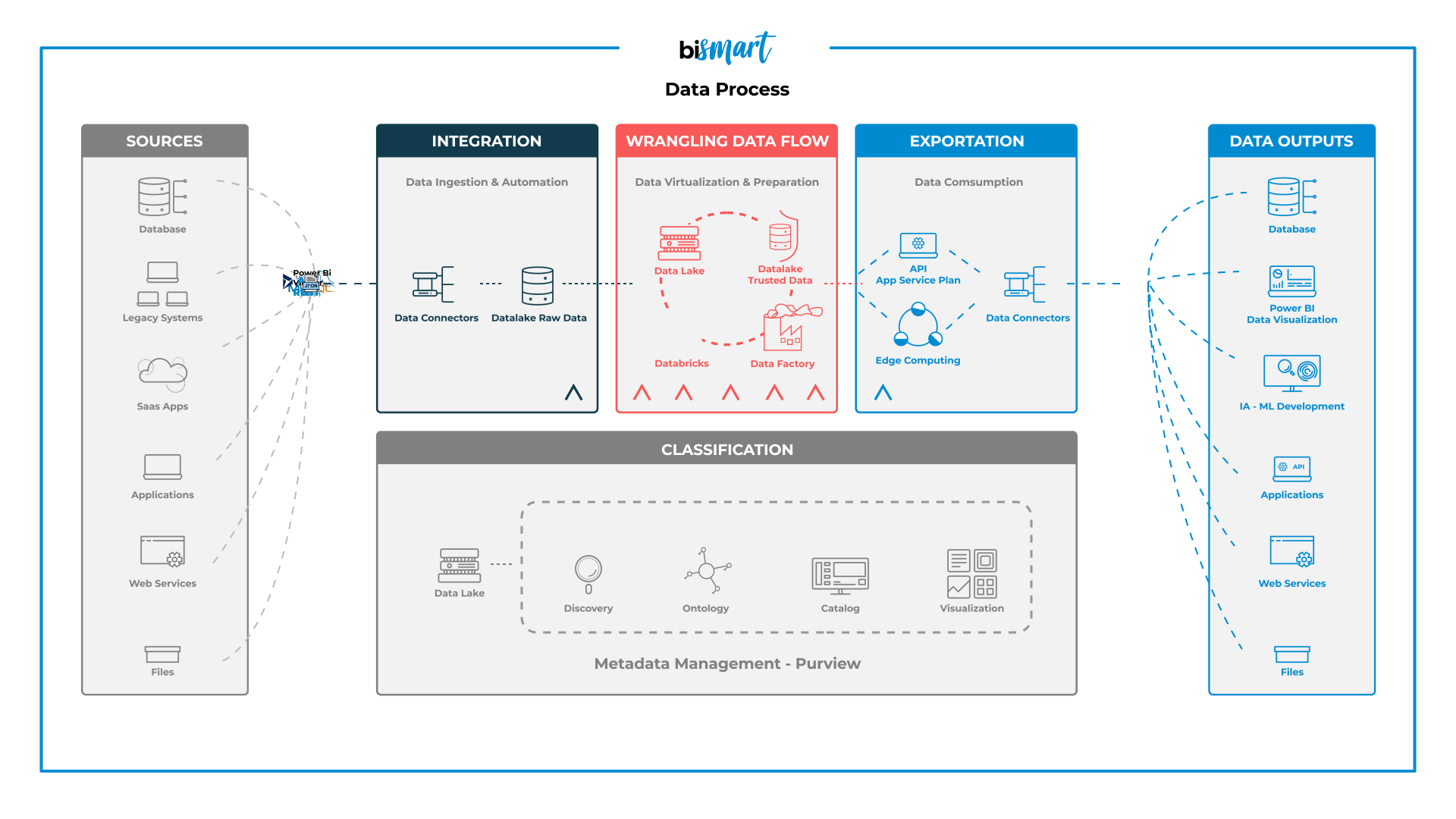
Hoy en día, los datos habitan en múltiples espacios que conocemos como fuentes de datos. Con los años, las fuentes de origen de los datos se han multiplicado de la misma forma en la que lo han hecho los datos disponibles.
Localizar todas las fuentes de origen de los datos puede ser una tarea engorrosa, y es que los datos están en todas partes: plataformas analíticas, correos electrónicos, bases de datos, archivos de todo tipo, redes sociales, etc.
En Bismart tenemos la capacidad de extraer y recopilar datos de cualquier tipo de fuente, priorizando las fuentes de origen que pueden contener datos útiles:
- Bases de datos estructuradas y no estructuradas
- Sistemas corporativos heredados
- Aplicaciones SaaS
- Otras aplicaciones
- Servicios de Internet propios o externos
- Archivos en cualquier formato
2. Ingesta de datos
Una vez los datos han sido localizados y extraídos de sus fuentes de origen, deben ser unificados e integrados en un único espacio. Más allá de su almacenamiento en una única base de datos, lo importante de este proceso es que los datos deben ser tratados y transformados para que posteriormente puedan ser analizados en conjunto. Por ello, los datos se almacenan en un data lake, un tipo de base de datos que almacena datos sin procesar o, lo que es lo mismo, datos en bruto.
El proceso de puesta en común de los datos se conoce como integración de datos y, a su vez, depende de la integración de sistemas.
2. Clasificación de los datos
Una vez los datos están integrados deben ser clasificados. En este proceso se hace una primera clasificación de los macrodatos —grandes volúmenes de datos— en la que los datos inútiles o innecesarios son eliminados. Esto se conoce como limpieza de datos.
Esta etapa del proceso también incluye el mapping o mapeo de los datos: los metadatos se agregan y se fusionan para poder ser mapeados. Es decir, clasificados, identificados y ordenados. En nuestro conjunto de macrodatos en bruto encontraremos muchos datos duplicados que se repiten en múltiples archivos con distinta nomenclatura, formato, etc. Estos datos deben ser identificados y agregados a una tabla maestra para que los sistemas puedan entender que se trata de la misma información.
Por otro lado, los datos se ordenan según las necesidades empresariales: por áreas temáticas, por propósito, por períodos temporales, etc. En este sentido, el data management y el data governance cobran especial relevancia. La gestión de los datos es extremadamente importante y engloba cada una de las etapas del flujo de datos que implica su procesamiento. Las tareas de data governance y data management se suelen llevar a cabo con el software Azure Pureview, que facilita la administración y el control de los datos y permite a los científicos de datos construir un mapa holístico y en tiempo real del panorama global de datos a través de procesos automatizados.
Básicamente, el proceso de clasificación de los datos consiste en cruzar, ordenar y mapear los datos para darles un sentido y hacerlos inteligibles.
3. Transformación y tratamiento de datos: "Wrangling Data Flow"
En inglés, el término "data wrangling" se utiliza para describir el proceso de limpieza y transformación de los datos. Básicamente, cuando los datos en bruto han sido recopilados y almacenados en el data lake, es el momento de prepararlos —limpiarlos, transformarlos y gestionarlos— para que, posteriormente, puedan ser utilizados en proyectos de business intelligence.
Los datos útiles ya clasificados, ordenados y mapeados se extraen del data lake y se organizan en plataformas tecnológicas de ingeniería de datos y data science como Azure Data Factory, que permite transformar los datos, ordenarlos, agregarlos, llevar a cabo pipelines y dataflows, etc.
La preparación de los datos también contempla otra herramienta: Azure Databricks. Databricks nos permite explorar, ejecutar y transformar macrodatos (estructurados y no estructurados). Sus principales funcionalidades son la transformación, preparación y análisis de los datos que posteriormente serán trasladados a otras plataformas para su consumo. Se trata de un entorno clave para la analítica y la transformación de los datos en información procesable.
Tanto Data Factory como Databricks son servicios intermedios entre las fuentes de origen de los datos y su destino final.
4. Exportación y consumo de datos
Una vez los datos están preparados para ser activados, son exportados a su destino final o temporal. En función del uso que queramos darles a los datos, serán consumidos por un tipo de plataforma u otra.
Los datos se pueden almacenar en bases de datos de destino —habitualmente un data warehouse— donde serán archivados de forma organizada y clasificada para su futuro uso.
También pueden ser consumidos por herramientas de análisis de datos y BI como Power BI, donde los datos serán analizados y transformados en historias mediante la visualización de datos y la creación de informes corporativos y cuadros de mando.
También podemos exportar los datos a otro tipo de plataformas analíticas de inteligencia artificial, machine learning y deep learning, o bien ser consumidos por APIs, web services o transformados en archivos.
La exportación de datos también requiere de procesos como el edge computing o proceso perimetral en español. Este modelo de computación distribuida que acerca al máximo la computación y el almacenamiento de los datos a la fuente de destino para acelerar los tempos del proceso y los tiempos de respuesta.
La extracción, transformación y carga de los datos se puede resumir en proceso ETL o ELT. Sin embargo, el flujo de datos necesario para extraer valor de los activos disponibles es mucho más completo que un proceso ETL y requiere de operaciones complementarias.
De la piedra al diamante: Transformación de los datos en valor empresarial
La especialidad de Bismart es la transformación de los datos en insights de negocio y en valor accionable que permita a las compañías optimizar sus procesos, tomar mejores decisiones de negocio, aumentar su productividad o diseñar mejores estrategias de acercamiento a los clientes, entre muchas otras cosas.
Para que todo esto suceda, los datos deben adentrarse en un proceso que incluye múltiples ciencias, involucra diferentes perfiles profesionales y requiere de diversas tecnologías.
En este artículo hemos descrito los pasos más destacados del flujo de un procesamiento de datos habitual. Sin embargo, el procesamiento de los datos puede variar según las necesidades de cada empresa. De hecho, debe hacerlo. No todas las compañías tienen las mismas necesidades y, evidentemente, el flujo de datos debe adaptarse a las características y objetivos de cada escenario corporativo.
En Bismart somos especialistas en buscar la mejor opción y el proceso más rentable para que puedas aprovechar los datos y transformarlos en business intelligence y valor empresarial. Nos adaptamos a cualquier tipo de entorno y diseñamos el proceso que sea más eficaz y rentable para ti.